MySQL-10.索引优化与查询优化
C-10.索引优化与查询优化
都有那些维度可以进行数据库调优?简言之:
- 索引失效,没有充分利用到索引 -- 索引建立
- 关联查询太多JOIN(设计缺陷或不得已的需求) -- SQL优化
- 服务器调优及各个参数设置(缓冲,线程数等) -- 调整my.cnf
- 数据过多 -- 分库分表
关于数据库调优的知识点非常分散。不同的DBMS,不同的公司,不同的职位,不同的项目遇到的问题都不尽相同。
虽然SQL查询优化的技术有很多,但是大方向上完全可以分成物理查询优化和逻辑查询优化两大块。
- 物理查询优化是通过
索引和表连接方式等技术来进行优化,这里重点需要掌握索引的使用。 - 逻辑查询优化就是通过SQL
等价变换提示查询效率,直白一点就是说,换一种查询写法执行效率可能更高。
1.数据准备
学院表50万条,班级表1万条。
步骤1,建表。
CREATE TABLE `class` (
`id` INT(11) NOT NULL AUTO_INCREMENT,
`className` VARCHAR(30) DEFAULT NULL,
`address` VARCHAR(40) DEFAULT NULL,
`monitor` INT NULL ,
PRIMARY KEY (`id`)
) ENGINE=INNODB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
CREATE TABLE `student` (
`id` INT(11) NOT NULL AUTO_INCREMENT,
`stuno` INT NOT NULL ,
`name` VARCHAR(20) DEFAULT NULL,
`age` INT(3) DEFAULT NULL,
`classId` INT(11) DEFAULT NULL,
PRIMARY KEY (`id`)
#CONSTRAINT `fk_class_id` FOREIGN KEY (`classId`) REFERENCES `t_class` (`id`)
) ENGINE=INNODB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
步骤2,设置参数。
set global log_bin_trust_function_creators=1;#命令开启:允许创建函数设置
步骤3,创建函数。
#随机产生字符串
DELIMITER //
CREATE FUNCTION rand_string(n INT) RETURNS VARCHAR(255)
BEGIN
DECLARE chars_str VARCHAR(100) DEFAULT
'abcdefghijklmnopqrstuvwxyzABCDEFJHIJKLMNOPQRSTUVWXYZ';
DECLARE return_str VARCHAR(255) DEFAULT '';
DECLARE i INT DEFAULT 0;
WHILE i < n DO
SET return_str =CONCAT(return_str,SUBSTRING(chars_str,FLOOR(1+RAND()*52),1));
SET i = i + 1;
END WHILE;
RETURN return_str;
END //
DELIMITER ;
#用于随机产生多少到多少的编号 随机产生班级编号
DELIMITER //
CREATE FUNCTION rand_num (from_num INT ,to_num INT) RETURNS INT(11)
BEGIN
DECLARE i INT DEFAULT 0;
SET i = FLOOR(from_num +RAND()*(to_num - from_num+1)) ;
RETURN i;
END //
DELIMITER ;
步骤4:创建存储过程
#创建往stu表中插入数据的存储过程
DELIMITER //
CREATE PROCEDURE insert_stu( START INT , max_num INT )
BEGIN
DECLARE i INT DEFAULT 0;
SET autocommit = 0; #设置手动提交事务
REPEAT #循环
SET i = i + 1; #赋值
INSERT INTO student (stuno, name ,age ,classId ) VALUES
((START+i),rand_string(6),rand_num(1,50),rand_num(1,1000));
UNTIL i = max_num
END REPEAT;
COMMIT; #提交事务
END //
DELIMITER ;
#假如要删除
#drop PROCEDURE insert_stu;
#执行存储过程,往class表添加随机数据
DELIMITER //
CREATE PROCEDURE `insert_class`( max_num INT )
BEGIN
DECLARE i INT DEFAULT 0;
SET autocommit = 0;
REPEAT
SET i = i + 1;
INSERT INTO class ( classname,address,monitor ) VALUES
(rand_string(8),rand_string(10),rand_num(1,100000));
UNTIL i = max_num
END REPEAT;
COMMIT;
END //
DELIMITER ;
#假如要删除
#drop PROCEDURE insert_class;
步骤5:调用存储过程
#执行存储过程,往class表添加1万条数据
CALL insert_class(10000);
#执行存储过程,往stu表添加50万条数据
CALL insert_stu(100000,500000);
步骤6:创建删除某表上索引存储过程
#创建存储过程
DELIMITER //
CREATE PROCEDURE `proc_drop_index`(dbname VARCHAR(200),tablename VARCHAR(200))
BEGIN
DECLARE done INT DEFAULT 0;
DECLARE ct INT DEFAULT 0;
DECLARE _index VARCHAR(200) DEFAULT '';
DECLARE _cur CURSOR FOR SELECT index_name FROM
information_schema.STATISTICS WHERE table_schema=dbname AND table_name=tablename AND
seq_in_index=1 AND index_name <>'PRIMARY' ;
#每个游标必须使用不同的declare continue handler for not found set done=1来控制游标的结束
DECLARE CONTINUE HANDLER FOR NOT FOUND set done=2 ;
#若没有数据返回,程序继续,并将变量done设为2
OPEN _cur;
FETCH _cur INTO _index;
WHILE _index<>'' DO
SET @str = CONCAT("drop index " , _index , " on " , tablename );
PREPARE sql_str FROM @str ;
EXECUTE sql_str;
DEALLOCATE PREPARE sql_str;
SET _index='';
FETCH _cur INTO _index;
END WHILE;
CLOSE _cur;
END //
DELIMITER ;
#执行存储过程
CALL proc_drop_index("dbname","tablename");
2.索引失效案例
MySQL中提高性能的一个最有效的方式就是对数据表设计合理的索引。索引提供了高效访问数据的方法,并且加快查询的速度,因此索引对查询的速度有着至关重要的影响。
- 使用索引可以
快速定位表中的某条数据,从而提高数据库查询的数据,提高数据库的性能。 - 如果查询没有使用索引,查询语句就会
扫描表中的所有记录。在数据量大的情况下,这样查询的速度会很慢。
大多数情况下(默认)采用B+树来构建索引。只是空间列类型的索引使用R-树,并且MEMORY表还支持hash索引。
其实,用不用索引,最终都是优化器说了算。优化器是基于什么的优化器?基于cost开销(CostBaseOptimizer),它不是基于规则(Rule-BaseOptimizer),也不是基于语义。怎样开销小,就怎么来。另外,SQL语句是否使用索引,跟数据库版本、数据量、数据选择度都有关系。
2.1 全值匹配
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE age=30;
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE age=30 AND classId=4;
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE age=30 AND classId=4 AND NAME = 'abcd';
建立索引前执行
mysql> SELECT SQL_NO_CACHE * FROM student WHERE age=30 AND classId=4 AND NAME = 'abcd';
Empty set, 1 warning (0.09 sec)
建立索引
#创建索引
CREATE INDEX idx_age ON student(age);
CREATE INDEX idx_age_classid ON student(age,classId);
CREATE INDEX idx_age_classid_name ON student(age,classId,NAME);
建立索引后执行
mysql> SELECT SQL_NO_CACHE * FROM student WHERE age=30 AND classId=4 AND NAME = 'abcd';
Empty set, 1 warning (0.00 sec)
2.2 最佳左前缀规则
在MySQL建立联合索引时,会遵守最佳左前缀匹配原则,即最左优先,在检索数据时从联合索引的最左边开始匹配。
#1.只能使用上 idx_age索引
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE student.age=30 AND student.name = 'abcd' ;
#2.不能使用上索引
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE student.classid=1 AND student.name = 'abcd';
#3.使用idx_age_classid_name索引
EXPLAIN SELECT SQL_NO_CACHE * FROM student
WHERE classid=4 AND student.age=30 AND student.name = 'abcd';
原因分析:
因为在构建联合索引对应的B+树时,每个页(包括叶子和非叶子)中,的一条数据存储的列的值的顺序,是定义索引的顺序,所以只有where子句中,存在联合索引的最左侧的列,才可能使用的上该联合索引。
对于上述第一条SQL的分析,为什么只能用idx_age索引,也是同理,对于idx_age_classid_name索引,age列和name列中有个classid列,如果只出现了age列,和name列,就会导致中间断了。
也就是说,联合索引(a,b,c),最佳顺序就是 a = ? and b = ? and c = ?。这样是最完美的使用联合索引的方式,但是只有a,c的话,就会导致无法使用该索引。因为使用a = ? 确定几条数据后,必须使用b列去过滤数据了,但是此时where子句中没有b的条件,所以就无法使用此索引树,去确定满足后面条件的数据了,非要使用此索引的话,可能会导致回表次数过多,执行效率低。
对于第三条SQL,能使用上idx_age_classid_name索引的分析,因为有查询优化器的存在,虽然在where子句中写的条件的顺序是,先classid 后age后name,但是查询优化器,会做一个操作,尝试将条件子句的顺序,转换成联合索引定义的顺序,从而完美的使用的联合索引。
#删除这两个索引
DROP INDEX idx_age ON student;
DROP INDEX idx_age_classid ON student;
#再次执行该语句
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE student.age=30 AND student.name = 'abcd' ;
#这里不展示具体执行结果,直接说结论
#使用上了idx_age_classid_name索引,但是key_len的长度是5
#而age列是int类型,且可以为null 4 + 1刚好是5B
#也就是说,该条语句只使用了联合索引的age列进行过滤,然后根据对应的id值,进行回表,在use where进行过滤。符合上面的原因分析
结论:MySQL可以为一张表的多个字段创建索引,一个索引可以包括16个字段。对于多列索引,过滤条件要使用索引必须按照索引的建立顺序,依次满足,一但跳过某个字段,索引后面的字段都无法使用。如果查询条件中没有使用这些字段中第1字段时,联合索引将失效。也即不会被使用。
扩展Alibaba《Java开发手册》
索引文件具有B-Tree的最左匹配特性,如果左边的之值未确定,那么无法使用该索引。
2.3 主键插入顺序
对于一个使用InnoDB存储引擎的表来说,在我们没有显式的创建索引时,表中的数据实际上都是存储在聚簇索引的叶子节点的。而记录又是存储在数据页中的,数据页和记录又是按照记录主键值从小到大的顺序进行排序,所以如果我们插入的记录的主键值是依次增大的话,那我们每插满一个数据页就换到下一个数据页继续插,而如果我们插入的主键值忽大忽小的话,就比较麻烦了,假设某个数据页存储的记录已经满了,它存储的主键值在1~100之间:

如果此时再插入一条主键为9的记录,那它插入的位置就如下图:

可这个数据页已经满了,再插进来咋办呢?我们需要把当前页面分裂成两个页面,把本页中的一些记录移动到新创建的这个页中。页面分裂和记录移位意味着什么?意味着: 性能损耗 !所以如果我们想尽量避免这样无谓的性能损耗,最好让插入的记录的主键值依次递增,这样就不会发生这样的性能损耗了。所以我们建议:让主键具有AUTO_INCREMENT,让存储引擎自己为表生成主键,而不是我们手动插入 ,
我们自定义的主键列 id 拥有AUTO_INCREMENT属性,在插入记录时存储引擎会自动为我们填入自增的主键值。这样的主键占用空间小,顺序写入,减少页分裂。
2.4 计算、函数导致索引失效
CREATE INDEX idx_name ON student(`name`);
#此语句比下一条要好!(能够使用上索引)
#执行结果使用上索引 idx_name
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE student.name LIKE 'abc%';
#未使用索引 type列的值是ALL 全表扫描
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE LEFT(student.name,3) = 'abc';
#原因,在使用完函数后,MySQL只能根据函数的结果,去和给定的值,对比。所以无法使用上索引
CREATE INDEX idx_sno ON student(stuno);
#未使用索引 type列的值是ALL 全表扫描
EXPLAIN SELECT SQL_NO_CACHE id, stuno, NAME FROM student WHERE stuno+1 = 900001;
#原因,在进行计算后,MySQL只能根据计算的结果,去和给定的值,对比。所以无法使用上索引
#执行结果使用上索引 idx_sno
EXPLAIN SELECT SQL_NO_CACHE id, stuno, NAME FROM student WHERE stuno = 900000;
2.5 类型转换导致索引失效
#无法使用idx_name索引 type列是ALL 全表扫描
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE NAME = 123;
#相当于,MySQL,对于类型不匹配的,会尝试使用隐式的函数转换成目标类型,这样就会导致无法使用索引。
#使用idx_name索引
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE NAME = '123';
2.6 范围条件右边的列索引失效
右边,是指在联合索引的列的右边的列,而不是where子句中的右边的列无法被使用。
SHOW INDEX FROM student;
#根据数据库和表名删除除主键外的索引
CALL proc_drop_index('atguigudb3','student');
#创建联合索引
CREATE INDEX idx_age_classId_name ON student(age,classId,`name`);
#会使用上idx_age_classId_name 但是key_len的长度是10
#age和classId都是int类型,都可以为null 所以是 4 + 1 + 4 + 1=10B 也就是在联合索引中,未使用上name列
#1.
EXPLAIN SELECT SQL_NO_CACHE * FROM student
WHERE student.age=30 AND student.classId > 20 AND student.name = 'abc' ;
#创建一个age,name,classId的索引
CREATE INDEX idx_age_name_cid ON student(age,`name`,classId);
#可以使用idx_age_name_cid索引
EXPLAIN SELECT SQL_NO_CACHE * FROM student
WHERE student.age=30 AND student.name = 'abc' AND student.classId>20;
#此时执行第一条语句,也会使用idx_age_name_cid,因为mysql会自动改变条件条件子句的顺序
应用开发中范围查询,例如:金额查询,日期查询往往都是范围查询。应该把查询条件放在where语句最后。(创建的联合索引中,务必把范围涉及到的字段写在最后)
2.7 不等于(!= 或 <>)索引失效
CREATE INDEX idx_name ON student(NAME);
#不能使用idx_name索引 type列的值是ALL
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE student.name <> 'abc' ;
#不能使用idx_name索引 type列的值是ALL
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE student.name != 'abc' ;
2.8 is null可以使用索引,is not null无法使用索引
#可以使用idx_age_classId_name索引
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE age IS NULL;
#无法使用索引 type列的值是ALL
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE age IS NOT NULL;
结论:最好在设计数据表的时候就将字段设置为 NOT NULL约束,比如你可以将INT类型的字段默认值设置为0。将字符类型的默认值设置为空字符串('‘)。
拓展:同理,在查询中使用not like 也无法使用索引,导致全表扫描。
2.9 like以通配符%开头索引失效
在使用LIKE关键字进行查询的sql中,如果匹配字符串"%"开头的,索引就会失效。只有"%"不在第一个位置,索引才会起作用。
#使用idx_name索引
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE NAME LIKE 'ab%';
#无法使用idx_name索引
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE NAME LIKE '%ab%';
拓展:Alibaba《Java开发手册》
【强制】页面搜索严禁左模糊或者全模糊,如果需要请走搜索引擎来解决。
2.10 OR前后存在非索引的列,索引失效
在WHERE子句中,如果在OR前的条件列进行了索引,而在OR后的条件列没有进行索引,那么索引会失效。也就是说,OR前后的两个条件中的列都是索引时,查询中才使用索引。
因为OR的含义就是两个只要满足一个即可,因此只有一个条件列进行了索引是没有意义的,只要有条件列没有进行索引,就会进行全表扫描,因此索引的条件列也会失效。
查询语句使用OR关键字的情况:
CALL proc_drop_index('atguigudb3','student');
CREATE INDEX idx_age ON student(age);
#type列的值是ALL
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE age = 10 OR classid = 100;
CREATE INDEX idx_cid ON student(classid);
#建立该索引后,执行,type 值是index_merge索引合并
2.11 数据库和表的字符集统一使用utf8mb4
统一使用utf8mb4( 5.5.3版本以上支持)兼容性更好,统一字符集可以避免由于字符集转换产生的乱码。不同的字符集进行比较前需要进行转换会造成索引失效。
2.12 建议
一般性建议:
-
对子单列索引,尽量选择针对当前query过滤性更好的索引。
-
在选择组合索引的时候,当前query中过滤性最好的字段在索引字段顺序中,位置越靠前越好。
-
在选择组合索引的时候,尽量选择能够包含当前query中的where子句中更多字段的索引。
-
在选择组合索引的时候,如果某个字段可能出现范围查询时,尽量把这个字段放在索引次序的最后面。
总之,书写SQL语句时,尽量避免造成索引失效的情况。
3.关联查询优化
3.1 数据准备
#分类
CREATE TABLE IF NOT EXISTS `type` (
`id` INT(10) UNSIGNED NOT NULL AUTO_INCREMENT,
`card` INT(10) UNSIGNED NOT NULL,
PRIMARY KEY (`id`)
);
#图书
CREATE TABLE IF NOT EXISTS `book` (
`bookid` INT(10) UNSIGNED NOT NULL AUTO_INCREMENT,
`card` INT(10) UNSIGNED NOT NULL,
PRIMARY KEY (`bookid`)
);
#向分类表中添加20条记录
INSERT INTO `type`(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO `type`(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO `type`(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO `type`(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO `type`(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO `type`(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO `type`(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO `type`(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO `type`(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO `type`(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO `type`(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO `type`(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO `type`(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO `type`(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO `type`(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO `type`(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO `type`(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO `type`(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO `type`(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO `type`(card) VALUES(FLOOR(1 + (RAND() * 20)));
#向图书表中添加20条记录
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
3.2 左外连接
mysql> EXPLAIN SELECT SQL_NO_CACHE * FROM `type` LEFT JOIN book ON type.card = book.card

指向结果看,type都是ALL
添加索引优化
CREATE INDEX idx_book_card ON book(card); #被驱动表建立索引,避免全表扫描
mysql> EXPLAIN SELECT SQL_NO_CACHE * FROM `type` LEFT JOIN book ON type.card = book.card;

可以看到第二行的 type 变为了 ref,rows 也变成了1优化比较明显。这是由左连接特性决定的。LEFT JOIN条件用于确定如何从右表搜索行,左边一定都有,所以右边是我们的关键点,一定需要建立索引。这是因为,在外连接中的特性是,左外连接中,左表是主表,左表中的数据是一定要保存的,所以,就必须对左表进行全表扫描。而从表的连接字段建立索引的话,就可以使用索引,去优化使用主表的数据,在从表中查询的这一步骤。
CREATE INDEX idx_type_card ON `type`(card); #驱动表的连接列,建立索引
mysql> EXPLAIN SELECT SQL_NO_CACHE * FROM `type` LEFT JOIN book ON type.card = book.card;

从结果看,type表虽然也使用了,索引,但是rows的行数是20,也就是说,还是相当于扫描了全表,不过使用索引优化了这一步。
DROP INDEX idx_book_card ON book;#移除被驱动表card列索引
mysql> EXPLAIN SELECT SQL_NO_CACHE * FROM `type` LEFT JOIN book ON type.card = book.card;

被驱动表book变回了ALL全表扫描。
3.3 采用内连接
DROP INDEX idx_type_card ON type;#移除type表的card列索引
使用inner join,内连接,没有主从表之分。由select查询优化器自己根据查询成本,选择驱动表和被驱动表。
mysql> EXPLAIN SELECT SQL_NO_CACHE * FROM type INNER JOIN book ON type.card=book.card;

CREATE INDEX idx_book_card ON book(card);#book表添加card列索引,优化
EXPLAIN SELECT SQL_NO_CACHE * FROM `type` INNER JOIN book ON type.card=book.card;

CREATE INDEX idx_type_card ON type(card);#type表添加card列索引,优化
EXPLAIN SELECT SQL_NO_CACHE * FROM `type` INNER JOIN book ON type.card=book.card;

DROP INDEX idx_type_card ON book;
EXPLAIN SELECT SQL_NO_CACHE * FROM `type` INNER JOIN book ON type.card=book.card;

结论:对于内连接来讲,如果表的连接条件中只能有一个字段有索引,则有索引的字段所在的表会被作为被驱动表出现。
#再次添加book表card列的索引
CREATE INDEX idx_book_card ON book(card);
#向type表中添加数据(20条数据)
INSERT INTO `type`(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO `type`(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO `type`(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO `type`(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO `type`(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO `type`(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO `type`(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO `type`(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO `type`(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO `type`(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO `type`(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO `type`(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO `type`(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO `type`(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO `type`(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO `type`(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO `type`(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO `type`(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO `type`(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO `type`(card) VALUES(FLOOR(1 + (RAND() * 20)));
EXPLAIN SELECT SQL_NO_CACHE * FROM `type` INNER JOIN book ON type.card = book.card;

结论:对于内连接来说,在两个表的连接条件都存在索引的情况下,会选择小表作为驱动表。“小表驱动大表”。
3.4 JOIN语句原理
join方式连接多个表,本质就是各个表之间数据的循环匹配。MySQL5.5版本之前,MySQL只支持一种表间关联方式,就是嵌套循环(Nested Loop Join)。如果关联表的数据量很大,则join关联的执行时间会非常长。在MySQL5.5以后的版本中,MySQL通过引入BNLJ算法来优化嵌套执行。
1.驱动表和被驱动表
- 内连接
SELECT * FROM A JOIN B ON ...
A一定是驱动表吗?不一定,优化器会根据你查询语句做优化,决定先查哪张表。先查询的表就是驱动表,反之就是被驱动表。使用explain关键字查看。
- 外连接
SELECT * FROM A LEFT JOIN B ON ...
#或
SELECT * FROM A RIGHT JOIN B ON ...
#4)JOIN的底层原理
CREATE TABLE a(f1 INT, f2 INT, INDEX(f1))ENGINE=INNODB;
CREATE TABLE b(f1 INT, f2 INT)ENGINE=INNODB;
INSERT INTO a VALUES(1,1),(2,2),(3,3),(4,4),(5,5),(6,6);
INSERT INTO b VALUES(3,3),(4,4),(5,5),(6,6),(7,7),(8,8);
#测试1
EXPLAIN SELECT * FROM a LEFT JOIN b ON(a.f1=b.f1) WHERE (a.f2=b.f2);

结论,从结果看,b是驱动表,a是被驱动表。这是底层将sql语句改写成内连接,这是因为WHERE (a.f2=b.f2) a,b都是只有两个字段,都相等就是内连接。所以,外连接也不一定主表就是驱动表。当然很少上述这种情况。
2.Simple Nested-Loop Join(简单嵌套循环连接)
在连接条件上都无索引的情况下,算法相当简单,从表A中取一条数据,遍历B表,将匹配成功的记录,当到临时表,以此类推,驱动表A的每一张表与被驱动表进行判断。
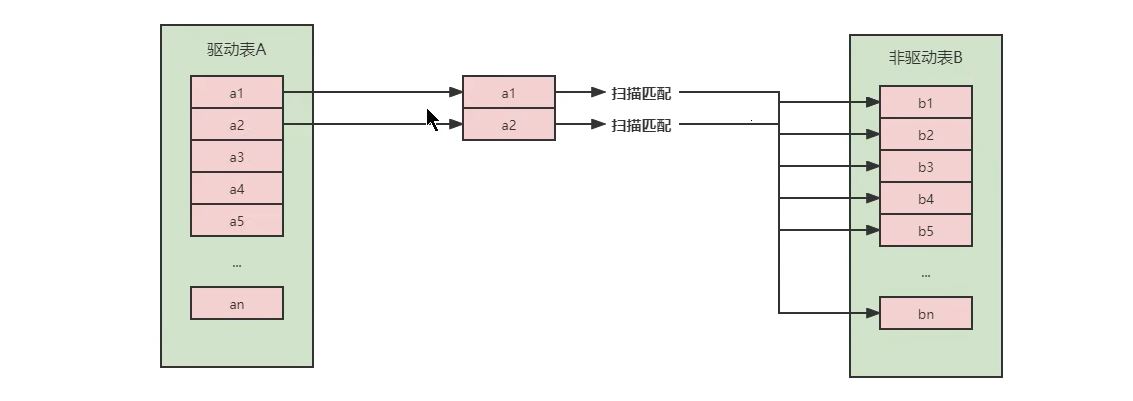
这种方式效率很低,上述表A数据100条,B数据1000条计算,A*B=10万次。
A代表A表的条数,B代表B表的条数(条数是指,满足ON条件且满足WHERE条件的行数)
| 开销统计 | SNLJ |
|---|---|
| 外表扫描次数 | 1 |
| 内表扫描次数 | A |
| 读取记录数 | A + B*A |
| JOIN比较次数 | B * A |
| 回表读取记录次数 | 0 |
当然mysql不会使用这中方式进行表的连接,后面出现了Nested-Loop Join优化算法。
3.Index Nested-Loop Join(索引嵌套循环连接)
Index Nested-Loop Join其优化的思路主要是为了减少内层表数据的匹配次数,所以要求被驱动表上的连接条件列上必须有索引才行。通过外层表匹配条件直接与内层表索引进行匹配,避免和内层表的每条记录去进行比较,这样极大的减少了对内层表的匹配次数。
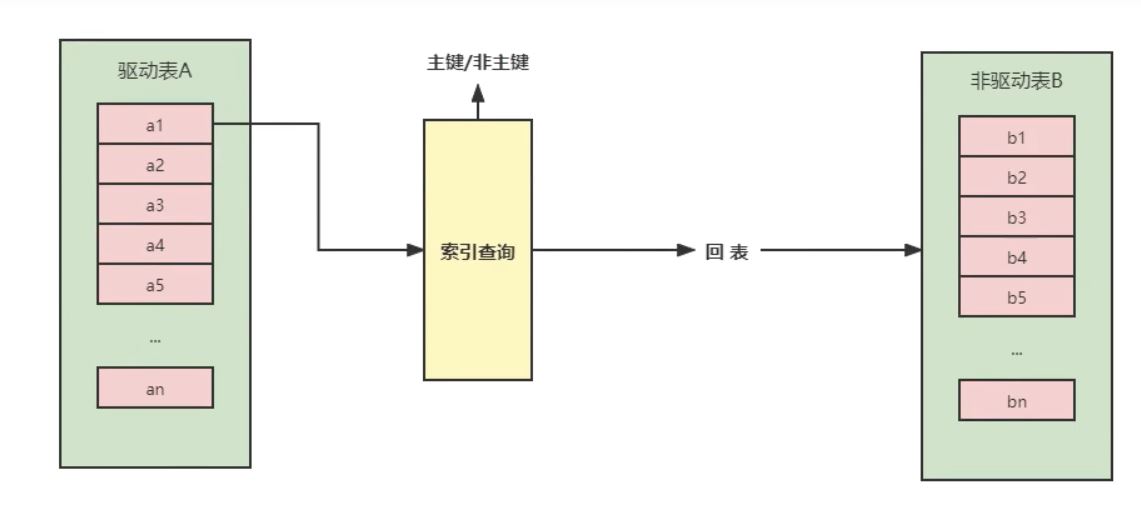
驱动表中的每条记录通过被驱动表的索引进行访问,因为索引查询的成本是比较固定的,故mysql优化器都倾向于使用记录数少的表作为驱动表(外表)。
A代表A表的条数,B代表B表的条数(条数是指,满足ON条件且满足WHERE条件的行数)
| 开销统计 | SNLJ | INLJ |
|---|---|---|
| 外表扫描次数 | 1 | 1 |
| 内表扫描次数 | A | 0 |
| 读取记录数 | A + B*A | A + B(匹配) |
| JOIN比较次数 | B * A | A*Index(索引数的层数) |
| 回表读取记录次数 | 0 | B(匹配的记录条数) |
4.Block Nested-Loop Join(块嵌套循环连接)
如果存在索引,那么会使用index的方式进行join,如果join的列没有索引,被驱动表要扫描的次数太多了。每次访问被驱动表,其表中的记录都会被加载到内存中,然后再从驱动表中取一条与其匹配,匹配结束后清除内存,然后再从驱动表中加载一条记录,然后把被驱动表的记录在加载到内存匹配,这样周而复始,大大增加了IO的次数。为了减少被驱动表的IO次数,就出现了Block Nested-Loop Join的方式。
不再是逐条获取驱动表的数据,而是一块一块的获取,引入了join buffer缓冲区,将驱动表join相关的部分数据列(大小受join buffer的限制)缓存到join buffer中,然后全表扫描被驱动表,被驱动表的每一条记录一次性和join buffer中的所有驱动表记录进行匹配(内存中操作),将简单嵌套循环中的多次比较合并成一次,降低了被驱动表的访问频率。
注意:
这里缓存的不只是关联表的列, select后面的列也会缓存起来。
在一个有N个join关联的sql中会分配N-1个join buffer。所以查询的时候尽量减少不必要的字段,可以让join buffer中可以存放更多的列。
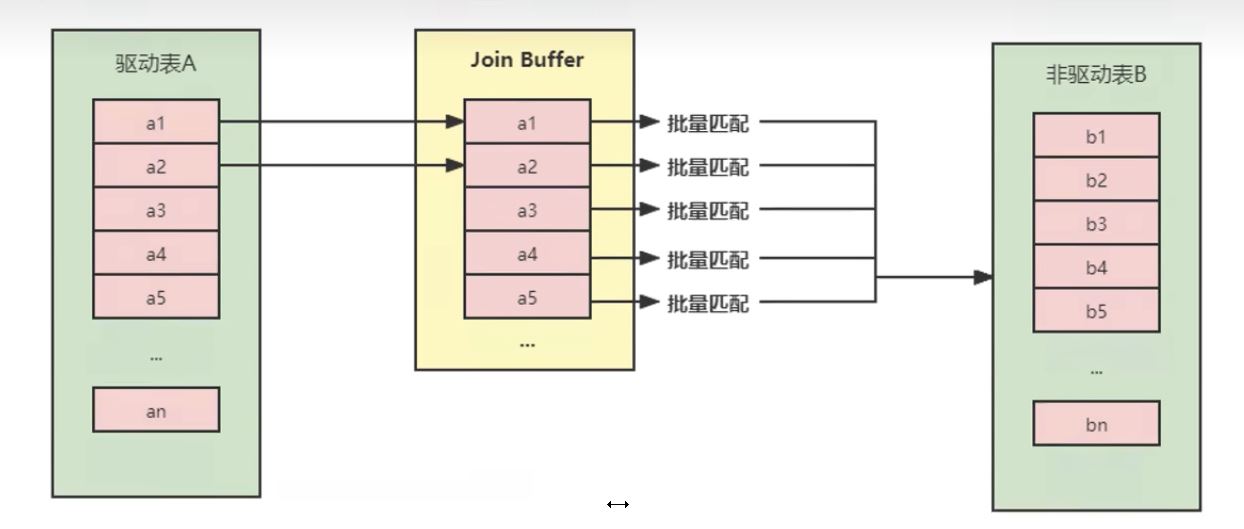
驱动表中的每条记录通过被驱动表的索引进行访问,因为索引查询的成本是比较固定的,故mysql优化器都倾向于使用记录数少的表作为驱动表(外表)。
A代表A表的条数,B代表B表的条数(条数是指,满足ON条件且满足WHERE条件的行数)
| 开销统计 | SNLJ | INLJ | BNLJ |
|---|---|---|---|
| 外表扫描次数 | 1 | 1 | 1 |
| 内表扫描次数 | A | 0 | (A * used_column_size) / join_buffer_size + 1(如果能整除不加1) |
| 读取记录数 | A + B*A | A + B(匹配) | A + B * (A * used_column_size / join_buffer_size) |
| JOIN比较次数 | B * A | A*Index(索引数的层数) | B * A |
| 回表读取记录次数 | 0 | B(匹配的记录条数) | 0 |
参数设置
- block_nested_loop
SHOW VARIABLES LIKE '%optimizer_switch%';#指令查看默认是开启的
- join_buffer_size
驱动表能不能一次加载完,要看join buffer能不能存储所有的数据,默认情况下join_buffer_size=256k。
mysql> SHOW VARIABLES LIKE 'join_buffer_size';
+------------------+--------+
| Variable_name | Value |
+------------------+--------+
| join_buffer_size | 262144 |
+------------------+--------+
1 row in set (0.01 sec)
join_buffer_size的最大值在32位系统可以申请4G,而在64位操做系统下可以申请大于4G的Join Buffer空间(64位Windows除外,其大值会被截断为4GB并发出警告)。
5.Join小结
1、整体效率比较:INLJ > BNLJ > SNLJ
2、永远用小结果集驱动大结果集(其本质就是减少外层循环的数据数量) (小的度量单位指的是表行数*每行大小)
select t1.b, t2.* from t1 straight_join t2 on (t1.b=t2.b) where t2.id<=100;#推荐
#straight_join查询优化器不对主表和从表做修改,左边的一定是驱动表
select t1.b, t2.* from t2 straight_join t1 on (t1.b=t2.b) where t2.id<=100;#不推荐
#上述原因,是因为选择了查询的列中,t1表只用了b列,而t2表用来所有的列,
#选择t1做驱动表的话,通用的join_buffer_size大小下,存储的t1表的条数就多,内存循环,也即是查询被驱动表的次数就少
3、为被驱动表匹配的条件增加索引(减少内层表的循环匹配次数)
4、增大join buffer size的大小(一次缓存的数据越多,那么内层包的扫表次数就越少)
5、减少驱动表不必要的字段查询(字段越少,join buffer所缓存的数据就越多)
6.Hash Join
从MySQL的8.0.20版本开始将废弃BNLJ,因为从MySQL8.0.18版本开始就加入了hash join默认都会使用hash join
- Nested Loop:
对于被连接的数据子集较小的情况,Nested Loop是个较好的选择。 - Hash Join是做大数据集连接时的常用方式,优化器使用两个表中较小(相对较小)的表利用Join Key在内存中建立散列表,然后扫描较大的表并探测散列表,找出与Hash表匹配的行。
- 这种方式适用于较小的表完全可以放于内存中的情况,这样总成本就是访问两个表的成本之和。
- 在表很大的情况下并不能完全放入内存,这时优化器会将它分割成
若干不同的分区,不能放入内存的部分就把该分区写入磁盘的临时段,此时要求有较大的临时段从而尽量提高I/O的性能。 - 它能够很好的工作于没有索引的大表和并行查询的环境中,并提供最好的性能。大多数人都说它是Join的重型升降机。Hash Join只能应用于等值连接(如WHERE A.COL1=B.COL2),这是由Hash的特点决定的。

3.5 小结
- 保证被驱动表的JOIN字段已经创建了索引。
- 需要JOIN的字段,数据类型保持绝对一致。
- LEFT JOIN时,选择将小表作为驱动表,
大表作为被驱动表。减少外层循环的次数。 - INNER JOIN时,MySQL会自动将
小结果集的表选为驱动表。选择相信MySQL的优化策略。 - 能够直接多表关联的尽量直接关联,不用子查询。(减少查询的次数)
- 不建议使用子查询,建议将子查询SQL拆开结合程序多次查询,或使用JOIN来替代子查询。
- 衍生表建不了索引。
4.子查询优化
MySQL从4.1版本开始支持子查询,使用子查询可以进行SELECT语句的嵌套查询,即一个SELECT查询的结果作为另一个SELECT语句的条件。子查询可以一次性完成很多逻辑上需要多个步骤才能完成的SQL操作。
子查询是 MySQL 的一项重要的功能,可以帮助我们通过一个 SQL 语句实现比较复杂的查询。但是,子查询的执行效率不高。
原因:
① 执行子查询时,MySQL需要为内层查询语句的查询结果建立一个临时表,然后外层查询语句从临时表中查询记录。查询完毕后,再撤销这些临时表。这样会消耗过多的CPU和IO资源,产生大量的慢查询。
② 子查询的结果集存储的临时表,不论是内存临时表还是磁盘临时表都不会存在索引,所以查询性能会受到一定的影响。
③ 对于返回结果集比较大的子查询,其对查询性能的影响也就越大。
在MySQ中,可以使用连接(JOIN)查询来替代子查询。连接查询不需要建立临时表,其速度比子查询要快,如果查询中使用索引的话,性能就会更好。
#创建班级表中班长的索引
CREATE INDEX idx_monitor ON class(monitor);
#查询班长的信息
EXPLAIN SELECT * FROM student a
WHERE a.`stuno` IN (
SELECT monitor
FROM class c
WHERE monitor IS NOT NULL
);
#子查询转成多表联查
EXPLAIN SELECT a.* FROM student a JOIN class c
ON a.`stuno` = c.`monitor`
WHERE c.`monitor` IS NOT NULL;
#查询不为班长的信息
EXPLAIN SELECT * FROM student stu1
WHERE stu1.`stuno` NOT IN (
SELECT monitor
FROM class c
WHERE monitor IS NOT NULL
);
EXPLAIN SELECT SQL_NO_CACHE a.* FROM student a LEFT OUTER JOIN class b
ON a.`stuno` = b.`monitor`
WHERE b.`monitor` IS NULL;
结论:尽量不要使用NOT IN或者 NOT EXISTS,用LEFT JOIN xxx ON xx WHERE xxx IS NULL替代
5.排序优化
5.1 排序优化
问题:在WHERE条件字段上加索引但是为什么在ORDER BY字段上还要加索引呢?
回答:
在MySQL中,支持两种排序方式,分别是FileSort和Index排序。
- lndex排序中,索引可以保证数据的有序性,不需要再进行排序,效率更高。
- FileSort 排序则一般在内存中进行排序,占用CPU较多。如果待排结果较大,会产生临时文件I/O到磁盘进行排序的情况,效率较低。
优化建议:
- 1.SQL 中,可以在 WHERE 子句和 ORDER BY 子句中使用索引,目的是在 WHERE 子句中
避免全表扫描,在 ORDER BY 子句避免使用 FileSort 排序。当然,某些情况下全表扫描,或者 FileSort 排序不一定比索引慢。但总的来说,我们还是要避免,以提高查询效率。 - 2.尽量使用 Index 完成 ORDER BY 排序。如果 WHERE 和 ORDER BY 后面是相同的列就使用单索引列;如果不同就使用联合索引。
- 3.无法使用 Index 时,需要对
FileSort方式进行调优。
5.2 测试
#删除class表和student表的非主键索引
CALL proc_drop_index('atguigudb3','class');
CALL proc_drop_index('atguigudb3','student');
SHOW INDEX FROM class;
SHOW INDEX FROM student;
#过程一:
#无索引
EXPLAIN SELECT SQL_NO_CACHE * FROM student ORDER BY age,classid;
#无索引
EXPLAIN SELECT SQL_NO_CACHE * FROM student ORDER BY age,classid LIMIT 10;
#过程二:order by时不limit,索引失效
#创建索引
CREATE INDEX idx_age_classid_name ON student (age,classid,NAME);
#不限制,索引失效 是因为,没有limit限制,对表的每一条数据都需要回表
#MySQL优化器觉得使用上索引 成本太高,不如filesort
EXPLAIN SELECT SQL_NO_CACHE * FROM student ORDER BY age,classid;
#覆盖索引 不用回表 MySQL优化器觉得使用上索引 成本低
#EXPLAIN SELECT SQL_NO_CACHE age,classid FROM student ORDER BY age,classid;
#增加limit过滤条件,使用上索引了。只用对10条,回表,优化器觉得成本低,可以使用索引
EXPLAIN SELECT SQL_NO_CACHE * FROM student ORDER BY age,classid LIMIT 10;
#过程三:order by时顺序错误,索引失效
#创建索引age,classid,stuno
CREATE INDEX idx_age_classid_stuno ON student (age,classid,stuno);
#以下哪些索引失效?
EXPLAIN SELECT * FROM student ORDER BY classid LIMIT 10;#×
EXPLAIN SELECT * FROM student ORDER BY classid,NAME LIMIT 10; #×
EXPLAIN SELECT * FROM student ORDER BY age,classid,stuno LIMIT 10;#√
EXPLAIN SELECT * FROM student ORDER BY age,classid LIMIT 10;#√
EXPLAIN SELECT * FROM student ORDER BY age LIMIT 10;#√
#过程四:order by时规则不一致, 索引失效 (顺序错,不索引;方向反,不索引)
EXPLAIN SELECT * FROM student ORDER BY age DESC, classid ASC LIMIT 10;#×
EXPLAIN SELECT * FROM student ORDER BY classid DESC, NAME DESC LIMIT 10;#×
EXPLAIN SELECT * FROM student ORDER BY age ASC,classid DESC LIMIT 10;#×
#这个可以使用上索引,因为在索引树中都是asc,而order by中都是降序的,反而可以使用上,倒着查询索引即可了
EXPLAIN SELECT * FROM student ORDER BY age DESC, classid DESC LIMIT 10;
#过程五:无过滤,不索引
#先过滤,在排序,即便组合索引中的列,在order by中,但是可能也是用不上
#这是因为优化器觉得,age=const(常量)过滤后,就只有很少的行数据,再进行索引的查询和回表,还不如
#直接filesort
#这里,本来应该使用上索引idx_age_classid_name 但是再explain的结果中key_len列是5
#即是,只是用到了age列的索引,因为正常age 是可以为null索引长度4 + 1 + classid可以为null + 4 + 1
# 加上name列可以为null 20 * 3 + 1 + 2(变长字段,描述真实的长度信息的字节空间) = 4 +1 + 4 +1 + 63 = 73
EXPLAIN SELECT * FROM student WHERE age = 45 ORDER BY classid;
EXPLAIN SELECT * FROM student WHERE age = 45 ORDER BY classid,NAME;
#使用不上索引
EXPLAIN SELECT * FROM student WHERE classid = 45 ORDER BY age;
#使用上了索引idx_age_classid_name 原因同上,不加limit需要回表太多,不如全表扫描
EXPLAIN SELECT * FROM student WHERE classid = 45 ORDER BY age LIMIT 10;
CREATE INDEX idx_cid ON student(classid);
EXPLAIN SELECT * FROM student WHERE classid=45 ORDER BY age;
#实战:测试filesort和index排序
CALL proc_drop_index('atguigudb3','student');
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE age = 30 AND stuno <101000 ORDER BY NAME ;
#方案一: 为了去掉filesort我们可以把索引建成
CREATE INDEX idx_age_name ON student(age,NAME);
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE age = 30 AND stuno <101000 ORDER BY NAME ;
#方案二:
CREATE INDEX idx_age_stuno_name ON student(age,stuno,NAME);
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE age = 30 AND stuno <101000 ORDER BY NAME ;
DROP INDEX idx_age_stuno_name ON student;
CREATE INDEX idx_age_stuno ON student(age,stuno);
#以上只是sql语句和对于执行计划的解释,并未展示结果,
5.3 案例实战
#实战:测试filesort和index排序
CALL proc_drop_index('atguigudb3','student');
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE age = 30 AND stuno <101000 ORDER BY NAME ;
#方案一: 为了去掉filesort我们可以把索引建成
CREATE INDEX idx_age_name ON student(age,NAME);
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE age = 30 AND stuno <101000 ORDER BY NAME ;
#方案二:
CREATE INDEX idx_age_stuno_name ON student(age,stuno,NAME);
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE age = 30 AND stuno <101000 ORDER BY NAME ;
DROP INDEX idx_age_stuno_name ON student;
CREATE INDEX idx_age_stuno ON student(age,stuno);
结论:
两个索引同时存在,mysql自动选择最优的方案。(对于这个例子,mysql选择idx_age_stuno_name)。但是, 随着数据量的变化,选择的索引也会随之变化的 。
当【范围条件】和【group by或者order by】的字段出现二选一时,优先观察条件字段的过滤数量,如果过滤的数据足够多,而需要排序的数据并不多时,优先把索引放在范围字段上。反之,亦然。
5.4 filesort算法:双路排序和单路排序
filesort有两种算法
双路排序 (慢)
MySQL 4.1之前是使用双路排序,字面意思就是两次扫描磁盘,最终得到数据, 读取行指针和order by列 ,对他们进行排序,然后扫描已经排序好的列表,按照列表中的值重新从列表中读取对应的数据输出。- 从磁盘取排序字段,在buffer进行排序,再从
磁盘取其他字段。
单路排序 (快)
从磁盘读取查询需要的所有列,按照order by列在buffer对它们进行排序,然后扫描排序后的列表进行输出, 它的效率更快一些,避免了第二次读取数据。并且把随机IO变成了顺序IO,但是它会使用更多的空间, 因为它把每一行都保存在内存中了。
结论及引申出的问题
-
由于单路是后出的,总体而言好过双路
-
但是用单路有问题
-
在sort_buffer中,单路比多路要
多占用很多空间,因为单路是把所有字段都取出,所以有可能取出的数据的总大小超出了sort_buffer的容量,导致每次只能取sort_buffer容量大小的数据,进行排序(创建tmp文件,多路合并),排完再取sort_buffer容量大小,再排......从而多次l/O。 -
单路本来想省一次l/o操作,
反而导致了大量的I/0操作,反而得不偿失。
-
优化策略
1.尝试提高sort_buffer_size
- 不管用哪种算法,提高这个参数都会提高效率,要根据系统的能力去提高,因为这个参数是针对每个进程(connection)的1M-8M之间调整。MySQL5.7,InnoDB存储引擎默认值是1048576字节,1MB
mysql> show variables like 'sort_buffer_size';
+------------------+--------+
| Variable_name | Value |
+------------------+--------+
| sort_buffer_size | 262144 |
+------------------+--------+
1 row in set (0.01 sec)
2.尝试提高max_length_for_sort_data
- 提高这个参数,会增加用单路排序的概率。
mysql> show variables like 'max_length_for_sort_data';
+--------------------------+-------+
| Variable_name | Value |
+--------------------------+-------+
| max_length_for_sort_data | 4096 |
+--------------------------+-------+
1 row in set (0.00 sec)
- 但是如果设的太高,数据总容量超出sort_buffer_size的概率就增大,明显症状是高的磁盘Io活动和低的处理器使用率。如果需要返回的列的总长度大于max_length_for_sort_data,使用双路算法,否则使用单路算法。1024-8192字节之间调整
3. Order by 时select * 是一个大忌。最好只Query需要的字段。
- 当Query的字段大小总和小于
max_length_for_sort_data,而且排序字段不是TEXTIBLOB类型时,会用改进后的算法――单路排序,否则用老算法――多路排序。 - 两种算法的数据都有可能超出sort_buffer_size的容量,超出之后,会创建tmp文件进行合并排序导致多次I/O,但是用单路排序算法的风险会更大一些,所以要
提高sort_buffer_size。
6.GROUP BY优化
- group by 使用索引的原则几乎跟order by一致 ,group by 即使没有过滤条件用到索引,也可以直接使用索引。
- group by 先排序再分组,遵照索引建的最佳左前缀法则。
- 当无法使用索引列,增大
max_length_for_sort_data和sort_buffer_size参数的设置。 - where效率高于having,能写在where限定的条件就不要写在having中了。
- 减少使用order by,和业务沟通能不排序就不排序,或将排序放到程序端去做。Order by、groupby、distinct这些语句较为耗费CPU,数据库的CPU资源是极其宝贵的。
- 包含了order by、group by、distinct这些查询的语句,where条件过滤出来的结果集请保持在1000行以内,否则SQL会很慢。
7.优化分页查询
一般分页查询时,通过创建覆盖索引能够比较好地提高性能。一个常见又非常头疼的问题就是limit 2000000,10,此时需要MySQL排序前2000000-2000010的记录,其他记录丢失,查询排序的代价非常大。
mysql> explain select * from student limit 2000000,10;

优化思路一
在索引上完成排序分页操作,最后根据主键关联回原表查询所需要的其他列内容
explain select * from student t,(select id from student order by id limit 2000000,10) a
where t.id = a.id;

优化思路二
该方案适用于主键自增的表,可以把Limit查询转换成某个位置的查询。
EXPLAIN SELECT * FROM student WHERE id > 2000000 LIMIT 10;

8.优先使用覆盖索引
8.1 什么是覆盖索引?
理解方式一:索引是高效找到行的一种方法,但是一般数据库也能使用索引找到一个列的数据,因此它不必读取整个行。毕竟索引叶子节点存储了它们索引的数据;当能通过读取索引可以得到想要的数据,就不需要读取行了。一个索引包含了满足查询结果的数据就叫做覆盖索引。
索引方式二:非聚簇索引的一种形式,它包括在查询里的SELECT,JOIN和WHERE子句用到的所有列(建索引的字段正好是覆盖查询条件中所设计的字段)。
简单说,就是索引列+主键包含SELECT到FROM之间查询的列。
举例一
#删除之间的索引
CALL proc_drop_index('atguigudb3','student');
CREATE INDEX idx_age_name ON student(age,`name`);
EXPLAIN SELECT * FROM student WHERE age != 20;

#上面查询失效案例,使用!=会导致索引失效,但从结果看,也使用了索引。这是因为覆盖索引现象
#这样也可以看出,上面讲的只是一般情况下的基本规则,方便理解查询优化器,但是也有特殊情况,
#因为是否使用索引,是由查询优化器基于成本的计算来选择的,所以要具体情况,具体分析。当然最好是,在业务代码中使用
#sql语句时,先explain查看一下。
EXPLAIN SELECT age,name,id FROM student WHERE age != 20;

举例二
#举例2
EXPLAIN SELECT * FROM student WHERE NAME LIKE '%abc';

#覆盖索引
EXPLAIN SELECT id,age,NAME FROM student WHERE NAME LIKE '%abc';

8.2 覆盖索引的利弊
好处:
1. 避免Innodb表进行索引的二次查询(回表)
Innodb是以聚集索引的顺序来存储的,对于Innodb来说,二级索引在叶子节点中所保存的是行的主键信息,如果是用二级索引查询数据,在查找到相应的键值后,还需通过主键进行二次查询才能获取我们真实所需要的数据。
在覆盖索引中,二级索引的键值中可以获取所要的数据,避免了对主键的二次查询,减少了IO操作,提升了查询效率。
2. 可以把随机IO变成顺序IO加快查询效率
由于覆盖索引是按键值的顺序存储的,对于IO密集型的范围查找来说,对比随机从磁盘读取每一行的数据IO要少的多,因此利用覆盖索引在访问时也可以把磁盘的随机读取的IO转变成索引查找的顺序IO。
由于覆盖索引可以减少树的搜索次数,显著提升查询性能,所以使用覆盖索引是一个常用的性能优化手段。
弊端:
索引字段的维护总是有代价的。因此,在建立冗余索引来支持覆盖索引时就需要权衡考虑了。这是业务DBA,或者称为业务数据架构师的工作。
9.如何给字符串添加索引
有一张教师表,表定义如下:
create table teacher(
ID bigint unsigned primary key,
email varchar(64),
...
)engine=innodb;
教师要使用邮箱登录,所以业务代码中一定会出现类似于这样的语句:
mysql> select col1, col2 from teacher where email='xxx';
如果email这个字段上没有索引,那么这个语句就只能做 全表扫描 。
9.1 前缀索引
MySQL是支持前缀索引的。默认地,如果你创建索引的语句不指定前缀长度,那么索引就会包含整个字符串。
mysql> alter table teacher add index index1(email);
#或
mysql> alter table teacher add index index2(email(6));
这两种不同的定义在数据结构和存储上有什么区别呢?下图就是这两个索引的示意图。

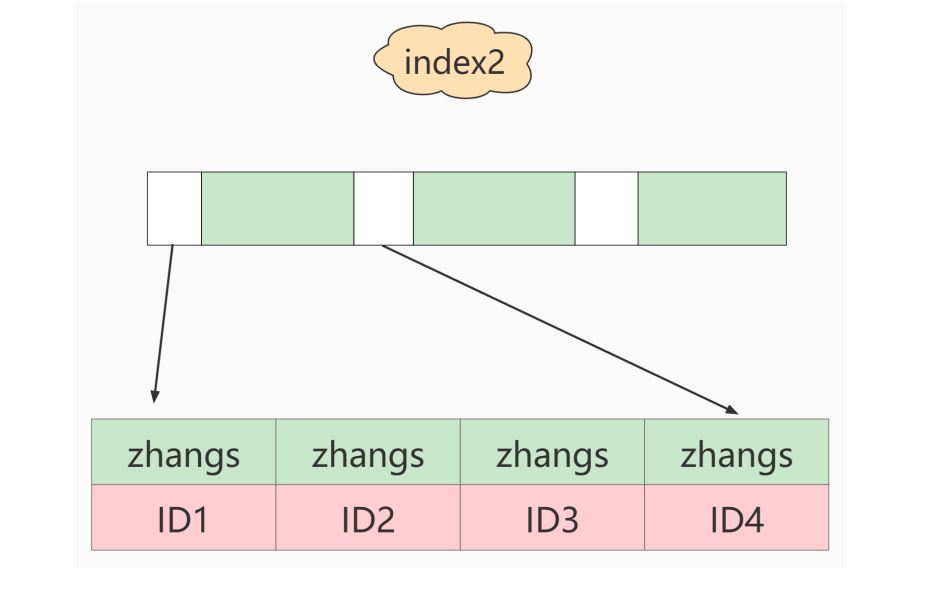
如果使用的是index1(即email整个字符串的索引结构),执行顺序是这样的:
1.从index1索引树找到满足索引值是’ [email protected] ’的这条记录,取得ID2的值;
2.到主键上查到主键值是ID2的行,判断email的值是正确的,将这行记录加入结果集;
3.取index1索引树上刚刚查到的位置的下一条记录,发现已经不满足email=' [email protected] ’的条件了,循环结束。
这个过程中,只需要回主键索引取一次数据,所以系统认为只扫描了一行。
如果使用的是index2(即email(6)索引结构),执行顺序是这样的:
1.从index2索引树找到满足索引值是’zhangs’的记录,找到的第一个是ID1;
2.到主键上查到主键值是ID1的行,判断出email的值不是’ [email protected] ’,这行记录丢弃;
3.取index2上刚刚查到的位置的下一条记录,发现仍然是’zhangs’,取出ID2,再到ID索引上取整行然后判断,这次值对了,将这行记录加入结果集;
4.重复上一步,直到在idxe2上取到的值不是’zhangs’时,循环结束。
也就是说使用前缀索引,定义好长度,就可以做到既节省空间,又不用额外增加太多的查询成本。前面已经讲过区分度,区分度越高越好。因为区分度越高,意味着重复的键值越少。见第八章,索引的创建和设计原则中的3.2小结中的9和10
9.2 前缀索引对覆盖索引的影响
结论:
使用前缀索引就用不上覆盖索引对查询性能的优化了,这也是你在选择是否使用前缀索引时需要考虑的一个因素。
10.索引条件下推(索引下推)
Index Condition Pushdown(ICP)是MySQL 5.6中新特性,是一种在存储引擎层使用索引过滤数据的一种优化方式。ICP可以减少存储引擎访问基表的次数以及MySQL服务器访问存储引擎的次数。
10.1 使用前后的扫描过程
在不使用ICP索引扫描的过程:
storage层:只将满足index key条件的索引记录对应的整行记录取出,返回给server层
server 层:对返回的数据,使用后面的where条件过滤,直至返回最后一行。
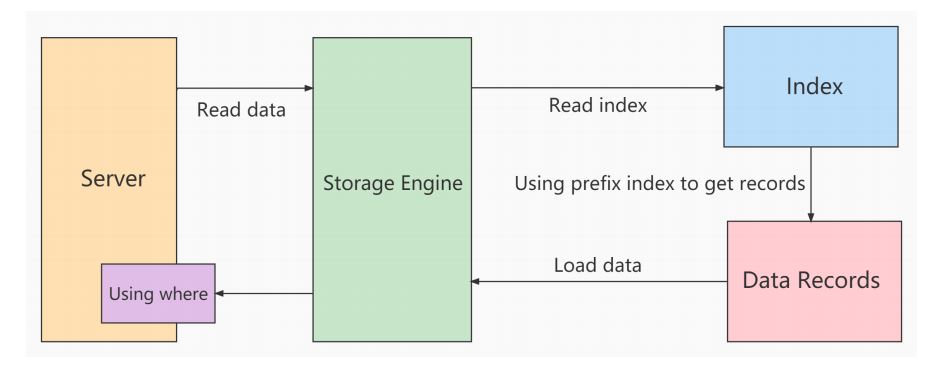
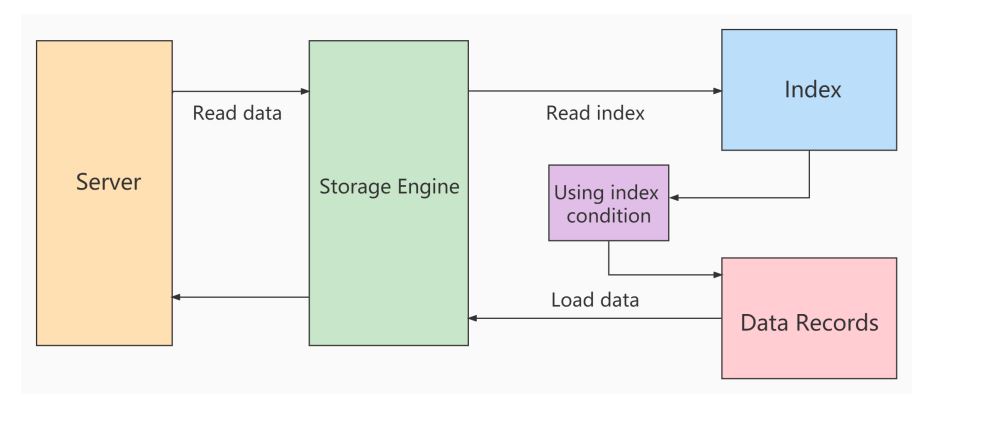
使用ICP扫描的过程:
- storage层:
首先将index key条件满足的索引记录区间确定,然后在索引上使用index filter进行过滤。将满足的index filter条件的索引记录才去回表取出整行记录返回server层。不满足index filter条件的索引记录丢弃,不回表、也不会返回server层。
- server 层:
对返回的数据,使用table filter条件做最后的过滤。
使用前后的成本差别
使用前,存储层多返回了需要被index filter过滤掉的整行记录
使用ICP后,直接就去掉了不满足index filter条件的记录,省去了他们回表和传递到server层的成本。
ICP的 加速效果 取决于在存储引擎内通过 ICP筛选 掉的数据的比例。
注意,索引条件下推,一般是用于组合索引中,就是在同一个索引树上,索引查询时,只是使用了部分索引,但是where条件中,还使用了索引树中的其他列,进行条件过滤,这时就先过滤条件,不直接根据部分索引的查询结果,进行回表操作。过滤条件执行后,满足的再进行回表操作。
10.2 ICP的使用条件
① 只能用于二级索引(secondary index)
②explain显示的执行计划中type值(join 类型)为range、ref、eq_ref或者ref_or_null。
③ 并非全部where条件都可以用ICP筛选,如果where条件的字段不在索引列中,还是要读取整表的记录到server端做where过滤。
④ ICP可以用于MyISAM和InnnoDB存储引擎
⑤ MySQL 5.6版本的不支持分区表的ICP功能,5.7版本的开始支持。
⑥ 当SQL使用覆盖索引时,不支持ICP优化方法。因为这种情况下使用ICP不能较少IO。
⑦相关子查询的条件不能使用ICP
10.3 开启和关闭索引下推
set optimizer_switch = 'index_condition_pushdown=on'#开启,关闭是off 默认是开启状态 不要关闭,因为确实会优化查询效率
不在举例,宋红康老师,课程中有举例,但我觉得,理解这个优化的设计思想就可以了。
11.普通索引 VS 唯一索引
从性能的角度考虑,你选择唯一索引还是普通索引呢?选择的依据是什么呢?
假设,我们有一个主键列为ID的表,表中有字段k,并且在k上有索引,假设字段 k 上的值都不重复。这个表的建表语句是:
mysql> create table test(
id int primary key,
k int not null,
name varchar(16),
index (k)
)engine=InnoDB;
表中R1~R5的(ID,k)值分别为(100,1)、(200,2)、(300,3)、(500,5)和(600,6)。
11.1 查询过程
假设,执行查询的语句是 select id from test where k=5。
- 对于普通索引来说,查找到满足条件的第一个记录(5,500)后,需要查找下一个记录,直到碰到第一个不满足k=5条件的记录。
- 对于唯一索引来说,由于索引定义了唯一性,查找到第一个满足条件的记录后,就会停止继续检索。
那么,这个不同带来的性能差距会有多少呢?答案是,微乎其微。
11.2 更新过程
为了说明普通索引和唯一索引对更新语句性能的影响这个问题,介绍一下change buffer。
当需要更新一个数据页时,如果数据页在内存中就直接更新,而如果这个数据页还没有在内存中的话,在不影响数据一致性的前提下, InooDB会将这些更新操作缓存在change buffer中,这样就不需要从磁盘中读入这个数据页了。在下次查询需要访问这个数据页的时候,将数据页读入内存,然后执行changebuffer中与这个页有关的操作。通过这种方式就能保证这个数据逻辑的正确性。
将change buffer中的操作应用到原数据页,得到最新结果的过程称为merge。除了访问这个数据页会触发merge外,系统有后台线程会定期merge。在数据库正常关闭(shutdown)的过程中,也会执行merge操作。
如果能够将更新操作先记录在change buffer,减少读磁盘,语句的执行速度会得到明显的提升。而且,数据读入内存是需要占用buffer pool的,所以这种方式还能够避免占用内存,提高内存利用率。
唯一索引的更新就不能使用change buffer,实际上也只有普通索引可以使用。
11.3 change buffer的使用场景
- 1.普通索引和唯一索引应该怎么选择?其实,这两类索引在查询能力上是没差别的,主要考虑的是对
更新性能的影响。所以,建议你尽量选择普通索引。 - 2.在实际使用中会发现,
普通索引和change buffer的配合使用,对于数据量大的表的更新优化还是很明显的。 - 3.如果所有的更新后面,都马上
伴随着对这个记录的查询,那么你应该关闭change buffer。而在其他情况下,change buffer都能提升更新性能。 - 4.由于唯一索引用不上change buffer的优化机制,因此如果
业务可以接受,从性能角度出发建议优先考虑非唯一索引。但是如果"业务可能无法确保"的情况下,怎么处理呢? - 首先,
业务正确性优先。我们的前提是“业务代码已经保证不会写入重复数据”的情况下,讨论性能问题。如果业务不能保证,或者业务就是要求数据库来做约束,那么没得选,必须创建唯一索引。这种情况下,本节的意义在于,如果碰上了大量插入数据慢、内存命中率低的时候,给你多提供一个排查思路。 - 然后,在一些“
归档库”的场景,你是可以考虑使用唯一索引的。比如,线上数据只需要保留半年,然后历史数据保存在归档库。这时候,归档数据已经是确保没有唯一键冲突了。要提高归档效率,可以考虑把表里面的唯一索引改成普通索引。
阿里开发规范
【强制】业务上具有唯一特性的字段,即使是多个字段的组合,也必须建成唯一索引。
说明:不要以为唯一索引影响了 insert 速度,这个速度损耗可以忽略,但提高查找速度是明显的;另外,即使在应用层做了非常完善的校验控制,只要没有唯一索引,根据墨菲定律,必然有脏数据产生。
12.其他优化策略
12.1 EXISTS 和 IN 的区分
问题
不太理解哪种情况下应该使用EXISTS,哪种情况应该用IN。选择的标准是看能否使用表的索引吗?
回答
索引是个前提,其实选择与否还是要看表的大小。你可以将选择的标准理解为小表驱动大表。在这种方式下效率是最高的。
举例
SELECT * FROM A WHERE cc IN ( SELECT cc FROM 3)
SELECT * FROM A WHERE EXISTS ( SELECT cc FROM B WHERE B.cc=A.cc)
当A表小于B时,用EXISTS,因为EXISTS的实现,相当于外表循环,实现逻辑类似于
for i in A
for j in B
if j.cc == i.cc then...
当B表小于A时,用IN
for i in B
for j in A
if j.cc == i.cc then...
那个表小就用那个表来驱动,A表小就用EXISTS,B表下用IN
12.2 COUNT(*)与COUNT(具体字段)效率
问:在 MySQL 中统计数据表的行数,可以使用三种方式:SELECT COUNT(*)、SELECT COUNT(1) 和SELECT COUNT(具体字段) ,使用这三者之间的查询效率是怎样的?
环节1: COUNT(*)和 COUNT(1)都是对所有结果进行COUNT,COUNT(*)和COUNT(1)本质上并没有区别(二者执行时间可能略有差别,不过你还是可以把它俩的执行效率看成是相等的)。如果有WHERE子句,则是对所有符合筛选条件的数据行进行统计;如果没有WHERE子句,则是对数据表的数据行数进行统计。
环节2: 如果是MyISAM存储引擎,统计数据表的行数只需要O(1)的复杂度,这是因为每张MyISAM的数据表都有一个meta信息存储了row_count值,而一致性则由表级锁来保证。
如果是InnoDB存储引擎,因为InnoDB支持事务,采用行级锁和MVCC机制,所以无法像MyISAM一样,维护一个row_count变量,因此需要采用扫描全表,是O(n)的复杂度,进行循环+计数的方式来完成统计。
环节3: 在InnoDB引擎中,如果采用COUNT(具体字段)来统计数据行数,要尽量采用二级索引。因为主键采用的索引是聚簇索引,聚簇索引包含的信息多,明显会大于二级索引(非聚簇索引)。对于COUNT(*)和COUNT(1)来说,它们不需要查找具体的行,只是统计行数,系统会自动采用占用空间更小的二级索引来进行统计。
如果有多个二级索引,会使用 key_len 小的二级索引进行扫描。当没有二级索引的时候,才会采用主键索引来进行统计。
12.3 关于SELECT(*)
在表查询中,建议明确字段,不要使用 * 作为查询的字段列表,推荐使用SELECT <字段列表> 查询。原因:
① MySQL 在解析的过程中,会通过 查询数据字典 将"*"按序转换成所有列名,这会大大的耗费资源和时间。
② 无法使用 覆盖索引
12.4 LIMIT 1 对优化的影响
针对的是会扫描全表的 SQL 语句,如果你可以确定结果集只有一条,那么加上LIMIT 1的时候,当找到一条结果的时候就不会继续扫描了,这样会加快查询速度。
如果数据表已经对字段建立了唯一索引,那么可以通过索引进行查询,不会全表扫描的话,就不需要加上LIMIT 1了。
12.5 多使用COMMIT
只要有可能,在程序中尽量多使用 COMMIT,这样程序的性能得到提高,需求也会因为 COMMIT 所释放的资源而减少。
COMMIT 所释放的资源:
- 回滚段上用于恢复数据的信息
- 被程序语句获得的锁
- redo / undo log buffer 中的空间
- 管理上述 3 种资源中的内部花费
13.淘宝订单,主键设计的学习
13.1 自增ID的问题
自增ID做主键,简单易懂,几乎所有数据库都支持自增类型,只是实现上各自有所不同而已。自增ID除了简单,其他都是缺点,总体来看存在以下几方面的问题:
1. 可靠性不高
存在自增ID回溯的问题,这个问题直到最新版本的MySQL 8.0才修复。自增ID回溯,是指在MySQL8.0之前,自增id的值,在mysql服务端重启后,会退回1。
2. 安全性不高
对外暴露的接口可以非常容易猜测对应的信息。比如:/User/1/这样的接口,可以非常容易猜测用户ID的值为多少,总用户数量有多少,也可以非常容易地通过接口进行数据的爬取。
3. 性能差
自增ID的性能较差,需要在数据库服务器端生成。
4. 交互多
业务还需要额外执行一次类似 last_insert_id() 的函数才能知道刚才插入的自增值,这需要多一次的网络交互。在海量并发的系统中,多1条SQL,就多一次性能上的开销。
5. 局部唯一性
最重要的一点,自增ID是局部唯一,只在当前数据库实例中唯一,而不是全局唯一,在任意服务器间都是唯一的。对于目前分布式系统来说,这简直就是噩梦。
13.2 业务字段做主键
为了能够唯一地标识一个会员的信息,需要为会员信息表设置一个主键。那么,怎么为这个表设置主键,才能达到我们理想的目标呢? 这里我们考虑业务字段做主键。
表数据如下:

在这个表里,哪个字段比较合适呢?
选择卡号(cardno)
会员卡号(cardno)看起来比较合适,因为会员卡号不能为空,而且有唯一性,可以用来 标识一条会员记录。
mysql> CREATE TABLE demo.membermaster
-> (
-> cardno CHAR(8) PRIMARY KEY, -- 会员卡号为主键
-> membername TEXT,
-> memberphone TEXT,
-> memberpid TEXT,
-> memberaddress TEXT,
-> sex TEXT,
-> birthday DATETIME
-> );
Query OK, 0 rows affected (0.06 sec)
不同的会员卡号对应不同的会员,字段“cardno”唯一地标识某一个会员。如果都是这样,会员卡号与会员一一对应,系统是可以正常运行的。
但实际情况是,会员卡号可能存在重复使用的情况。比如,张三因为工作变动搬离了原来的地址,不再到商家的门店消费了 (退还了会员卡),于是张三就不再是这个商家门店的会员了。但是,商家不想让这个会 员卡空着,就把卡号是“10000001”的会员卡发给了王五。
从系统设计的角度看,这个变化只是修改了会员信息表中的卡号是“10000001”这个会员 信息,并不会影响到数据一致性。也就是说,修改会员卡号是“10000001”的会员信息, 系统的各个模块,都会获取到修改后的会员信息,不会出现“有的模块获取到修改之前的会员信息,有的模块获取到修改后的会员信息,而导致系统内部数据不一致”的情况。因此,从信息系统层面上看是没问题的。
但是从使用系统的业务层面来看,就有很大的问题 了,会对商家造成影响
比如,我们有一个销售流水表(trans),记录了所有的销售流水明细。2020 年 12 月 01 日,张三在门店购买了一本书,消费了 89 元。那么,系统中就有了张三买书的流水记录,如下所示:

接着,我们查询一下 2020 年 12 月 01 日的会员销售记录:
mysql> SELECT b.membername,c.goodsname,a.quantity,a.salesvalue,a.transdate
-> FROM demo.trans AS a
-> JOIN demo.membermaster AS b
-> JOIN demo.goodsmaster AS c
-> ON (a.cardno = b.cardno AND a.itemnumber=c.itemnumber);
+------------+-----------+----------+------------+---------------------+
| membername | goodsname | quantity | salesvalue | transdate |
+------------+-----------+----------+------------+---------------------+
| 张三 | 书 | 1.000 | 89.00 | 2020-12-01 00:00:00 |
+------------+-----------+----------+------------+---------------------+
1 row in set (0.00 sec)
如果会员卡“10000001”又发给了王五,我们会更改会员信息表。导致查询时:
mysql> SELECT b.membername,c.goodsname,a.quantity,a.salesvalue,a.transdate
-> FROM demo.trans AS a
-> JOIN demo.membermaster AS b
-> JOIN demo.goodsmaster AS c
-> ON (a.cardno = b.cardno AND a.itemnumber=c.itemnumber);
+------------+-----------+----------+------------+---------------------+
| membername | goodsname | quantity | salesvalue | transdate |
+------------+-----------+----------+------------+---------------------+
| 王五 | 书 | 1.000 | 89.00 | 2020-12-01 00:00:00 |
+------------+-----------+----------+------------+---------------------+
1 row in set (0.01 sec)
这次得到的结果是:王五在 2020 年 12 月 01 日,买了一本书,消费 89 元。显然是错误的!结论:千万不能把会员卡号当做主键。
- 选择会员电话 或 身份证号
会员电话可以做主键吗?不行的。在实际操作中,手机号也存在被运营商收回,重新发给别人用的情况。
那身份证号行不行呢?好像可以。因为身份证决不会重复,身份证号与一个人存在一一对 应的关系。可问题是,身份证号属于个人隐私,顾客不一定愿意给你。要是强制要求会员必须登记身份证号,会把很多客人赶跑的。其实,客户电话也有这个问题,这也是我们在设计会员信息表的时候,允许身份证号和电话都为空的原因。
所以,建议尽量不要用跟业务有关的字段做主键。毕竟,作为项目设计的技术人员,我们谁也无法预测在项目的整个生命周期中,哪个业务字段会因为项目的业务需求而有重复,或者重用之类的情况出现。
经验:
刚开始使用 MySQL 时,很多人都很容易犯的错误是喜欢用业务字段做主键,想当然地认为了解业务需求,但实际情况往往出乎意料,而更改主键设置的成本非常高。
13.3 淘宝的主键设计
在淘宝的电商业务中,订单服务是一个核心业务。请问,订单表的主键淘宝是如何设计的呢?是自增ID吗?
打开淘宝,看一下订单信息:

从上图可以发现,订单号不是自增ID!我们详细看下上述4个订单号:
1550672064762308113
1481195847180308113
1431156171142308113
1431146631521308113
订单号是19位的长度,且订单的最后5位都是一样的,都是08113。且订单号的前面14位部分是单调递增的。
大胆猜测,淘宝的订单ID设计应该是:
订单ID = 时间 + 去重字段 + 用户ID后6位尾号
这样的设计能做到全局唯一,且对分布式系统查询及其友好。
13.4 推荐的主键设计
非核心业务:对应表的主键自增ID,如告警、日志、监控等信息。
核心业务:主键设计至少应该是全局唯一且是单调递增。全局唯一保证在各系统之间都是唯一的,单调递增是希望插入时不影响数据库性能。
这里推荐最简单的一种主键设计:UUID。
UUID的特点:
全局唯一,占用36字节,数据无序,插入性能差。
认识UUID:
- 为什么UUID是全局唯一的?
- 为什么UUID占用36个字节?
- 为什么UUID是无序的?
MySQL数据库的UUID组成如下所示:
UUID = 时间+UUID版本(16字节)- 时钟序列(4字节) - MAC地址(12字节)
我们以UUID值e0ea12d4-6473-11eb-943c-00155dbaa39d举例:

为什么UUID是全局唯一的?
在UUID中时间部分占用60位,存储的类似TIMESTAMP的时间戳,但表示的是从1582-10-15 00:00:00.00到现在的100ns的计数。可以看到UUID存储的时间精度比TIMESTAMPE更高,时间维度发生重复的概率降低到1/100ns。
时钟序列是为了避免时钟被回拨导致产生时间重复的可能性。MAC地址用于全局唯一。
为什么UUID占用36个字节?
UUID根据字符串进行存储,设计时还带有无用"-"字符串,因此总共需要36个字节。
为什么UUID是随机无序的呢?
因为UUID的设计中,将时间低位放在最前面,而这部分的数据是一直在变化的,并且是无序。
改造UUID
若将时间高低位互换,则时间就是单调递增的了,也就变得单调递增了。MySQL 8.0可以更换时间低位和时间高位的存储方式,这样UUID就是有序的UUID了。
MySQL 8.0还解决了UUID存在的空间占用的问题,除去了UUID字符串中无意义的"-"字符串,并且将字符串用二进制类型保存,这样存储空间降低为了16字节。
可以通过MySQL8.0提供的uuid_to_bin函数实现上述功能,同样的,MySQL也提供了bin_to_uuid函数进行转化
SET @uuid = UUID();
SELECT @uuid,uuid_to_bin(@uuid),uuid_to_bin(@uuid,TRUE);

通过函数uuid_to_bin(@uuid,true)将UUID转化为有序UUID了。全局唯一 + 单调递增,这不就是我们想要的主键!
4、有序UUID性能测试
16字节的有序UUID,相比之前8字节的自增ID,性能和存储空间对比究竟如何呢?
我们来做一个测试,插入1亿条数据,每条数据占用500字节,含有3个二级索引,最终的结果如下所示:

从上图可以看到插入1亿条数据有序UUID是最快的,而且在实际业务使用中有序UUID在业务端就可以生成。还可以进一步减少SQL的交互次数。
另外,虽然有序UUID相比自增ID多了8个字节,但实际只增大了3G的存储空间,还可以接受。
在当今的互联网环境中,非常不推荐自增ID作为主键的数据库设计。更推荐类似有序UUID的全局唯一的实现。
另外在真实的业务系统中,主键还可以加入业务和系统属性,如用户的尾号,机房的信息等。这样的主键设计就更为考验架构师的水平了。
如果不是MySQL8.0肿么办?
手动赋值字段做主键!
比如,设计各个分店的会员表的主键,因为如果每台机器各自产生的数据需要合并,就可能会出现主键重复的问题。
可以在总部 MySQL 数据库中,有一个管理信息表,在这个表中添加一个字段,专门用来记录当前会员编号的最大值。
门店在添加会员的时候,先到总部 MySQL 数据库中获取这个最大值,在这个基础上加 1,然后用这个值作为新会员的“id”,同时,更新总部 MySQL 数据库管理信息表中的当 前会员编号的最大值。
这样一来,各个门店添加会员的时候,都对同一个总部 MySQL 数据库中的数据表字段进 行操作,就解决了各门店添加会员时会员编号冲突的问题。
只是为了记录自己的学习历程,且本人水平有限,不对之处,请指正。