Mybatis执行器
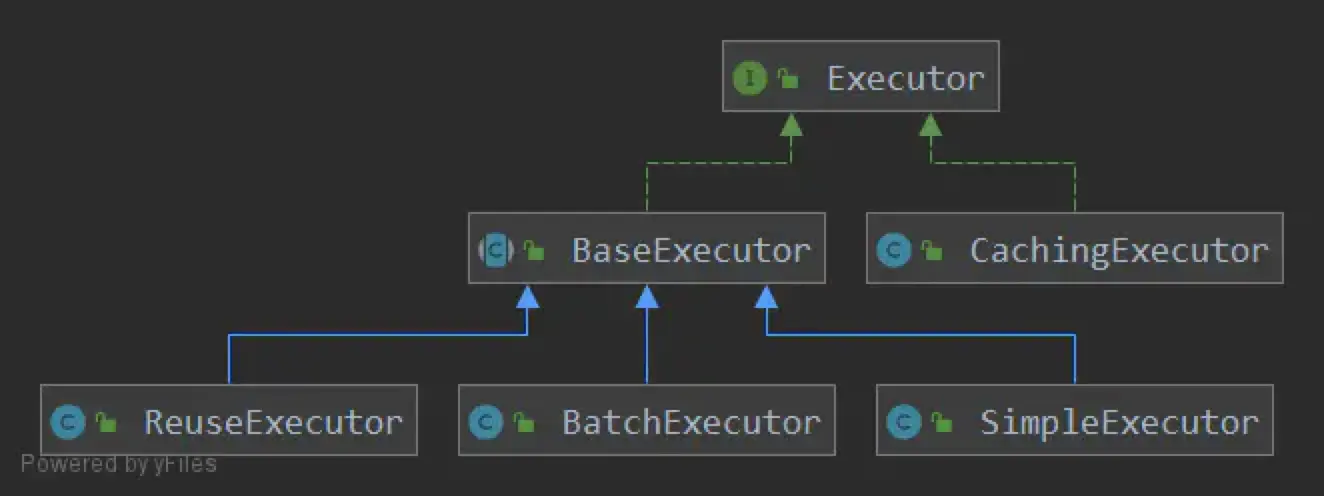
mybatis执行sql语句的操作是由执行器(Executor)完成的,mybatis中一共提供了3种Executor:
| 类型 | 名称 | 功能 |
|---|---|---|
REUSE |
重用执行器 | 缓存PreparedStatement,下一次执行相同的sql可重用 |
BATCH |
批量执行器 | 将修改操作记录在本地,等待程序触发或有下一次查询时才批量执行修改操作 |
SIMPLE |
简单执行器 | 对每一次执行都生成PreparedStatement,执行完就关闭,不缓存 |
另外,mybatis 还提供了一个缓存执行器CachingExecutor,该执行器实际上是以上三种执行器的装饰类,用以处理缓存相关操作,实际干活的还是以上三种执行器之一。
Executor的继续结构如下:
1. BaseExecutor
BaseExecutor实现了Executor的基本操作,如:
-
事务的处理:
commit(...):处理事务的提交rollback(...):处理事务的回滚
-
缓存的处理:
createCacheKey(...):创建缓存keyclearLocalCache(...):清除缓存
-
curd操作:
query(...):查询操作update(...):更新操作,插入与删除也是在这里处理
-
留待子类的实现
doUpdate(...):具体的更新操作,留待子类实现doQuery(...):具体的查询操作,留待子类实现
接下来我们关注Executor的实现时,只关注留待子类实现的方法。
2. SimpleExecutor
SimpleExecutor会对每一次执行都生成PreparedStatement,执行完就关闭,不缓存,我们来看看它是怎么实现的,来看看它的doQuery(...)方法:
public <E> List<E> doQuery(MappedStatement ms, Object parameter, RowBounds rowBounds,
ResultHandler resultHandler, BoundSql boundSql) throws SQLException {
Statement stmt = null;
try {
// 获取配置
Configuration configuration = ms.getConfiguration();
StatementHandler handler = configuration.newStatementHandler(wrapper, ms, parameter,
rowBounds, resultHandler, boundSql);
// 得到 PrepareStatement
stmt = prepareStatement(handler, ms.getStatementLog());
// 执行查询
return handler.query(stmt, resultHandler);
} finally {
// 关闭 Statement
closeStatement(stmt);
}
}
获取Statement的方法为SimpleExecutor#prepareStatement:
private Statement prepareStatement(StatementHandler handler, Log statementLog)
throws SQLException {
Statement stmt;
// 获取数据库连接
Connection connection = getConnection(statementLog);
// 获取 Statement
stmt = handler.prepare(connection, transaction.getTimeout());
// 处理参数设置
handler.parameterize(stmt);
return stmt;
}
这个方法先是获取了数据库连接,接着获取Statement,然后处理了参数设置。
关于数据库连接的获取,我们在分析配置文件的解析时,数据源的配置最终会转化成PooledDataSource或UnpooledDataSource对象,数据库连接就是从数据源来的。
至于Statement的生成,PreparedStatement的实例化操作方法为PreparedStatementHandler#instantiateStatement,这些都是常规的jdbc操作,就不细看了。
处理sql的执行方法为PreparedStatementHandler#query:
@Override
public <E> List<E> query(Statement statement, ResultHandler resultHandler) throws SQLException {
PreparedStatement ps = (PreparedStatement) statement;
// 执行
ps.execute();
return resultSetHandler.handleResultSets(ps);
}
SimpleExecutor#doQuery(...)的执行流程如下:
- 获取数据库连接
- 获取
PrepareStatement - 执行查询
- 关闭
PrepareStatement
SimpleExecutor的操作就是常规的jdbc操作。
3. ReuseExecutor
ReuseExecutor会缓存PreparedStatement,下一次执行相同的sql可重用。
我们依然分析doQuery(...)方法:
public <E> List<E> doQuery(MappedStatement ms, Object parameter, RowBounds rowBounds,
ResultHandler resultHandler, BoundSql boundSql) throws SQLException {
Configuration configuration = ms.getConfiguration();
StatementHandler handler = configuration.newStatementHandler(wrapper, ms, parameter,
rowBounds, resultHandler, boundSql);
// 获取 Statement
Statement stmt = prepareStatement(handler, ms.getStatementLog());
// 处理查询操作
return handler.query(stmt, resultHandler);
}
与SimpleExecutor相比,ReuseExecutor的doQuery(...)方法并没关闭Statement.我们来看看Statement的获取操作:
private Statement prepareStatement(StatementHandler handler, Log statementLog)
throws SQLException {
Statement stmt;
BoundSql boundSql = handler.getBoundSql();
String sql = boundSql.getSql();
// 根据sql语句判断是否有Statement缓存
if (hasStatementFor(sql)) {
// 有缓存,直接使用
stmt = getStatement(sql);
applyTransactionTimeout(stmt);
} else {
// 没缓存,获取数据库连接,再获取 Statement
Connection connection = getConnection(statementLog);
stmt = handler.prepare(connection, transaction.getTimeout());
// 缓存 Statement
putStatement(sql, stmt);
}
// 处理参数
handler.parameterize(stmt);
return stmt;
}
可以看到,ReuseExecutor获取Statement时,会先从缓存里获取,缓存里没有才会新建一个Statement,然后将新建的Statement添加到缓存中。从这里可以看出,ReuseExecutor的Reuse,复用的是Statement。
我们再来看看缓存Statement的结构:
public class ReuseExecutor extends BaseExecutor {
private final Map<String, Statement> statementMap = new HashMap<>();
...
private Statement getStatement(String s) {
return statementMap.get(s);
}
private void putStatement(String sql, Statement stmt) {
statementMap.put(sql, stmt);
}
}
由些可见,缓存Statement的是一个Map,key为sql语句,value为Statement.
4. BatchExecutor
BatchExecutor会将修改操作记录在本地,等待程序触发或有下一次查询时才批量执行修改操作,即:
- 进行修改操作(
insert,update,delete)时,并不会立即执行,而是会缓存到本地 - 进行查询操作(
select)时,会先处理缓存到本地的修改操作,再进行查询操作 - 也可行触发修改操作
从以上内容来看,这种方式似乎有大坑,列举几点如下:
- 修改操作缓存到本地后,如果执行前遇到意外重启,缓存的记录会不会丢失?
- 分布式环境下,多机共同协作,更新在A机上执行,查询在B机上执行,B机是不是不能查到B机的更新记录(B机的更新操作还在缓存中,并未执行)?
我们来看下BatchExecutor的更新操作,进入doUpdate(...)方法:
public int doUpdate(MappedStatement ms, Object parameterObject) throws SQLException {
final Configuration configuration = ms.getConfiguration();
final StatementHandler handler = configuration.newStatementHandler(this, ms, parameterObject,
RowBounds.DEFAULT, null, null);
final BoundSql boundSql = handler.getBoundSql();
final String sql = boundSql.getSql();
final Statement stmt;
// 如果传入的sql是当前保存的 sql,直接使用
if (sql.equals(currentSql) && ms.equals(currentStatement)) {
int last = statementList.size() - 1;
stmt = statementList.get(last);
applyTransactionTimeout(stmt);
handler.parameterize(stmt);// fix Issues 322
BatchResult batchResult = batchResultList.get(last);
batchResult.addParameterObject(parameterObject);
} else {
// 创建连接,获取 Statement
Connection connection = getConnection(ms.getStatementLog());
stmt = handler.prepare(connection, transaction.getTimeout());
handler.parameterize(stmt); // fix Issues 322
currentSql = sql;
currentStatement = ms;
statementList.add(stmt);
batchResultList.add(new BatchResult(ms, sql, parameterObject));
}
// 保存,等待之后批量执行
handler.batch(stmt);
return BATCH_UPDATE_RETURN_VALUE;
}
BatchExecutor有成员变量会记录上一次执行的sql与MappedStatement,如果本次执行的sql与MappedStatement与上一次执行的相同,则直接使用上一次的Statement,否则就新建连接、获取Statement.
得到Statement后,会调用PreparedStatementHandler#batch方法:
public void batch(Statement statement) throws SQLException {
PreparedStatement ps = (PreparedStatement) statement;
ps.addBatch();
}
这个方法并没有执行,只是调用PreparedStatement#addBatch方法,将当前statement保存了起来。
PreparedStatement#addBatch方法如何使用呢?简单示意下:
// 获取连接
Connection connection = getConnection();
// 预编译sql
String sql = "xxx";
PreparedStatement statement = connection.prepareStatement(sql);
//记录1
statement.setInt(1, 1);
statement.setString(2, "one");
statement.addBatch();
//记录2
statement.setInt(1, 2);
statement.setString(2, "two");
statement.addBatch();
//记录3
statement.setInt(1, 3);
statement.setString(2, "three");
statement.addBatch();
//批量执行
int[] counts = statement.executeBatch();
// 关闭statment,关闭连接
...
BatchExecutor的doUpdate(...)方法并没有执行sql语句,我们再来看看doQuery(...)方法:
public <E> List<E> doQuery(MappedStatement ms, Object parameterObject, RowBounds rowBounds,
ResultHandler resultHandler, BoundSql boundSql) throws SQLException {
Statement stmt = null;
try {
// 处理缓存中的 statements
flushStatements();
Configuration configuration = ms.getConfiguration();
StatementHandler handler = configuration.newStatementHandler(wrapper, ms, parameterObject,
rowBounds, resultHandler, boundSql);
// 获取连接,获取Statement,处理参数
Connection connection = getConnection(ms.getStatementLog());
stmt = handler.prepare(connection, transaction.getTimeout());
handler.parameterize(stmt);
// 执行查询
return handler.query(stmt, resultHandler);
} finally {
// 关闭 Statement
closeStatement(stmt);
}
}
doQuery(...)方法会先调用flushStatements()方法,然后再处理查询操作,整个过程基本同SimpleExecutor一致,即”获取数据库连接-获取Statement-处理查询-关闭Statement“等几步。我们重点来看flushStatements()方法的流程.
flushStatements()方法最终调用的是BatchExecutor#doFlushStatements方法,代码如下:
public List<BatchResult> doFlushStatements(boolean isRollback) throws SQLException {
try {
List<BatchResult> results = new ArrayList<>();
if (isRollback) {
return Collections.emptyList();
}
// 遍历的statementList,statementList就是缓存statement的结构
for (int i = 0, n = statementList.size(); i < n; i++) {
Statement stmt = statementList.get(i);
applyTransactionTimeout(stmt);
BatchResult batchResult = batchResultList.get(i);
try {
// 关键代码:stmt.executeBatch(),批量执行sql
batchResult.setUpdateCounts(stmt.executeBatch());
...
} catch (BatchUpdateException e) {
...
}
results.add(batchResult);
}
return results;
} finally {
...
}
}
BatchExecutor#doFlushStatements方法的关键代码就是batchResult.setUpdateCounts(stmt.executeBatch());了 ,其中的stmt.executeBatch()就是批量执行更新操作了。
从以上分析可知,BatchExecutor#doUpdate(...)方法不会执行sql语句,只是把sql语句转换为Statement然后缓存起来,在执行BatchExecutor#doQuery(...)方法时,会先执行缓存起来的Statement,然后再执行查询操作,当然也可以手动调用BatchExecutor#flushStatements方法执行缓存的Statement。
5. CachingExecutor
CachingExecutor不同于以上3种执行器,它是一个装饰类,可以从缓存中获取数据,实际干活的还是以上三种执行器之一:
public class CachingExecutor implements Executor {
// 具体的执行器
private final Executor delegate;
private final TransactionalCacheManager tcm = new TransactionalCacheManager();
public CachingExecutor(Executor delegate) {
this.delegate = delegate;
delegate.setExecutorWrapper(this);
}
...
}
从代码来看,它是Executor的子类,其中有一个成员变量delegate,它的类型为Executor,由构造方法传入。也就是说,在创建CachingExecutor时,会传入以上3种执行器之一,CachingExecutor会把它保存到成员变量delegate中。
CachingExecutor的query(...)方法如下:
public <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds,
ResultHandler resultHandler) throws SQLException {
BoundSql boundSql = ms.getBoundSql(parameterObject);
// 创建缓存key
CacheKey key = createCacheKey(ms, parameterObject, rowBounds, boundSql);
return query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
}
@Override
public <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds,
ResultHandler resultHandler, CacheKey key, BoundSql boundSql)
throws SQLException {
Cache cache = ms.getCache();
// 操作缓存
if (cache != null) {
flushCacheIfRequired(ms);
if (ms.isUseCache() && resultHandler ** null) {
ensureNoOutParams(ms, boundSql);
@SuppressWarnings("unchecked")
// 从缓存中获取
List<E> list = (List<E>) tcm.getObject(cache, key);
if (list ** null) {
// 实际处理查询的操作
list = delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
// 添加到缓存中
tcm.putObject(cache, key, list); // issue #578 and #116
}
return list;
}
}
return delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
}
从代码上来看,CachingExecutor在处理查询时,会先从缓存中获取,当缓存中不存在时,就执行具体执行器的query(xxx)方法。
热门相关:视死如归魏君子 医门宗师 离婚后她成了总裁 风流医圣 嫁入豪门后我养崽盘大佬