go.uber.org/ratelimit 源码分析
go.uber.org/ratelimit 源码分析
go 提供了一用来接口限流的包。其中"go.uber.org/ratelimit" 包正是基于漏桶算法实现的。
使用方式:
- 通过 ratelimit.New 创建限流器对象,参数为每秒允许的请求数(RPS)。
- 使用 Take() 方法来获取限流许可,该方法会阻塞请求知道满足限速要求。
官方示例:
import (
"fmt"
"time"
"go.uber.org/ratelimit"
)
func main() {
rl := ratelimit.New(100) // 每秒多少次
prev := time.Now()
for i := 0; i < 10; i++ {
now := rl.Take() // 平均时间
fmt.Println(i, now.Sub(prev))
prev = now
}
// Output:
// 0 0
// 1 10ms
// 2 10ms
// 3 10ms
// 4 10ms
// 5 10ms
// 6 10ms
// 7 10ms
// 8 10ms
// 9 10ms
}
ratelimit.New()指的是每秒平均多少次,在运行程序后,并不会严格按照官方给的样例输出。
源码分析
不仅知其然,还要知其所以然。
最大松弛量
传统的漏桶算法每隔请求的间隔是固定的,然而在实际上的互连网应用中,流量经常是突发性的。对于这种情况,uber引入了最大松弛量的概念。
假如我们要求每秒限定100个请求,平均每个请求间隔 10ms。但是实际情况下,有些间隔比较长,有些间隔比较短。如下图所示:
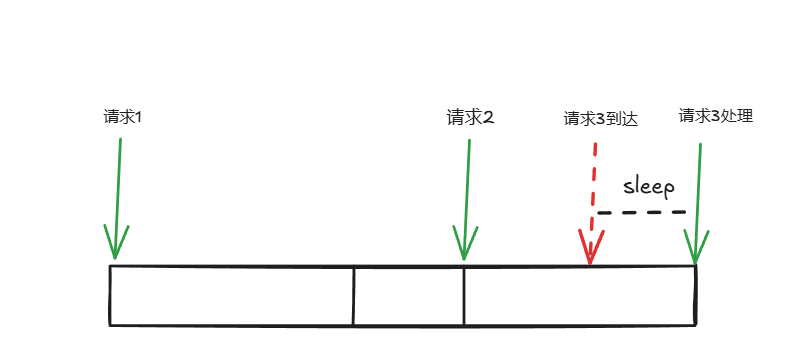
请求 1 完成后,15ms 后,请求 2 才到来,可以对请求 2 立即处理。请求 2 完成后,5ms 后,请求 3 到来,这个时候距离上次请求还不足 10ms,因此还需要等待 5ms。
但是,对于这种情况,实际上三个请求一共消耗了 25ms 才完成,并不是预期的 20ms。在 uber-go 实现的 ratelimit 中,可以把之前间隔比较长的请求的时间,匀给后面的使用,保证每秒请求数 (RPS) 即可。
了解完这个前缀知识就可以查看源码了。
New()
ratelimit.New() 内部调用的是 newAtomicInt64Based 方法。
type atomicInt64Limiter struct {
prepadding [64]byte // 填充字节,确保state独占一个缓存行
state int64 // 最后一次权限发送的纳秒时间戳,用于控制请求的速度
postpadding [56]byte // 填充字节,确保state独占一个缓存行
perRequest time.Duration // 限流器放行周期,用于计算下一个权限发送的state的值
maxSlack time.Duration // 最大松弛量
clock Clock // 指向当前时间获取函数的指针
}
// newAtomicBased返回一个新的基于原子的限制器。
func newAtomicInt64Based(rate int, opts ...Option) *atomicInt64Limiter {
config := buildConfig(opts) // 加载配置,config.per 默认为 1s,config.slack 默认为 10
perRequest := config.per / time.Duration(rate)
l := &atomicInt64Limiter{
perRequest: perRequest,
maxSlack: time.Duration(config.slack) * perRequest, // 默认maxSlack为perRequest 10倍
clock: config.clock,
}
atomic.StoreInt64(&l.state, 0)
return l
}
Take()
// Take blocks to ensure that the time spent between multiple
// Take calls is on average time.Second/rate.
func (t *atomicInt64Limiter) Take() time.Time {
var (
newTimeOfNextPermissionIssue int64 // 下一次允许请求的时间
now int64 // 当前时间
)
for {
now = t.clock.Now().UnixNano()
timeOfNextPermissionIssue := atomic.LoadInt64(&t.state) // 上一次允许请求时间
switch {
case timeOfNextPermissionIssue == 0 || (t.maxSlack == 0 && now-timeOfNextPermissionIssue > int64(t.perRequest)):
// if this is our first call or t.maxSlack == 0 we need to shrink issue time to now
newTimeOfNextPermissionIssue = now
case t.maxSlack > 0 && now-timeOfNextPermissionIssue > int64(t.maxSlack)+int64(t.perRequest):
// a lot of nanoseconds passed since the last Take call
// we will limit max accumulated time to maxSlack
newTimeOfNextPermissionIssue = now - int64(t.maxSlack)
default:
// calculate the time at which our permission was issued
newTimeOfNextPermissionIssue = timeOfNextPermissionIssue + int64(t.perRequest)
}
if atomic.CompareAndSwapInt64(&t.state, timeOfNextPermissionIssue, newTimeOfNextPermissionIssue) {
break
}
}
sleepDuration := time.Duration(newTimeOfNextPermissionIssue - now)
if sleepDuration > 0 {
t.clock.Sleep(sleepDuration)
return time.Unix(0, newTimeOfNextPermissionIssue)
}
// return now if we don't sleep as atomicLimiter does
return time.Unix(0, now)
}
switch 这块挺绕的,刚开始一直以为timeOfNextPermissionIssue 为下次放行的时间戳,这样的话当t.maxSlack = 0时,只要 now-timeOfNextPermissionIssue > 0 就应该放行。无法解释(t.maxSlack == 0 && now-timeOfNextPermissionIssue > int64(t.perRequest))。
让我们对上面的三个 case 分析一下
case 1
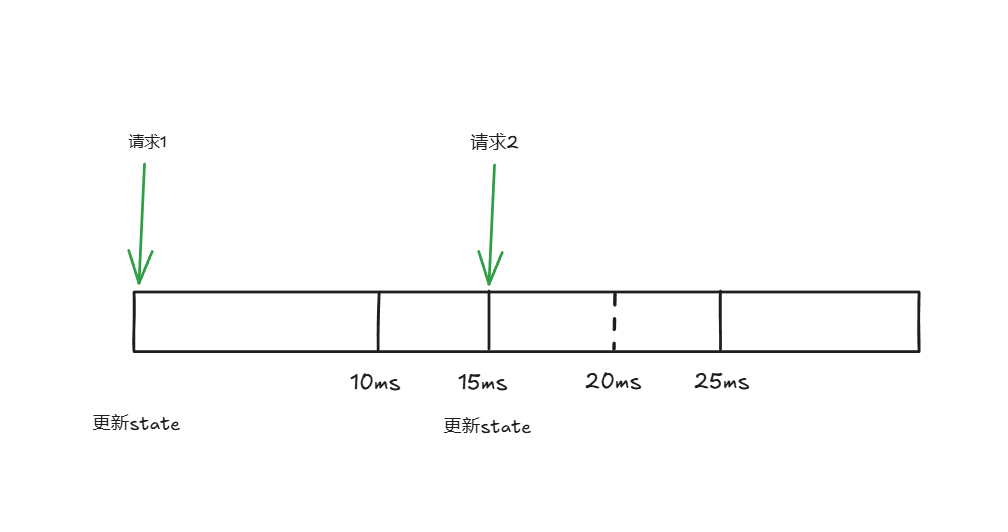
case timeOfNextPermissionIssue == 0 || (t.maxSlack == 0 && now-timeOfNextPermissionIssue > int64(t.perRequest))
这个比较好理解,我们仍以每秒100个请求为例,平均间隔 10ms。当本次请求时间与上次放行时间 > 时间间隔时即可放行,并记录本次访问时间,如图:
case 2
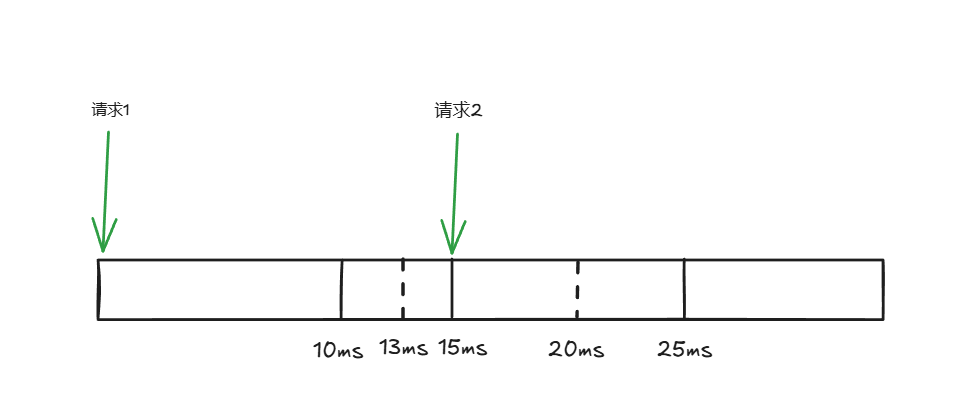
case t.maxSlack > 0 && now-timeOfNextPermissionIssue > int64(t.maxSlack)+int64(t.perRequest)
这块比较巧妙,假如松弛量是3 ms,当我们在第二次请求时的时间戳 > 13 ms,此时 newTimeOfNextPermissionIssue= now - maxSlack = 12 ms。
当 maxSlack 较大且与上次请求相隔较长时,后续的大量请求会被直接放行,以弥补此次浪费的时间。
假设第一次请求时间为0, maxSlack 为 100 ms,perRequest为10 ms,在第二次请求时与第一次间隔为 111 ms ,newTimeOfNextPermissionIssue = 111 - 100 = 11 ms。而 now 为 111 ms,限流器在后面的10次take中都会经过default直接放行,直到 newTimeOfNextPermissionIssue > now。
case 3
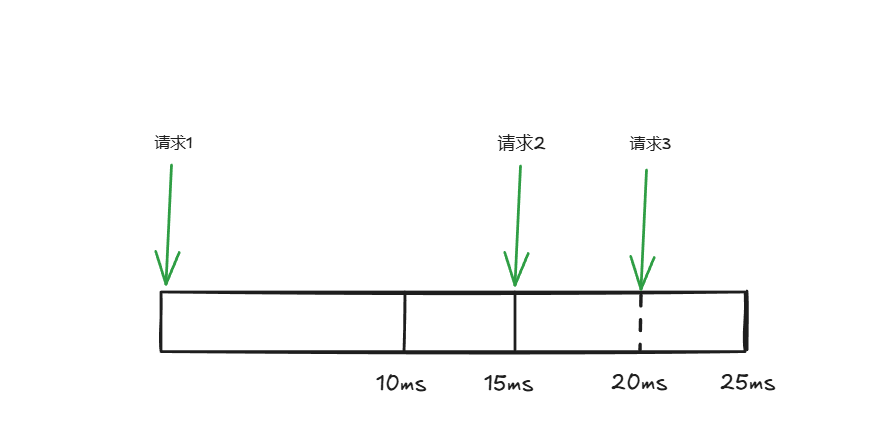
对于其它的请求, newTimeOfNextPermissionIssue = timeOfNextPermissionIssue + int64(t.perRequest)。
假如maxSlack为 100ms,perRequest 为 10ms,当请求2在15ms访问后,state 更新为 10ms,这样在请求3在20ms访问时,不会出现拦截的情况。
小结
uber 对基于漏桶实现的 ratelimit 进行了一些优化,让其限流更加的平滑。主要体现在两点:
- 本次请求时间距离上次放行时间 >
时间间隔 + 松弛量时,后面10次的请求会根据情况直接放行 时间间隔 + 松弛量>= 本次请求时间距离上次放行时间 >时间间隔,state = state + perRequest