《REBEL Relation Extraction By End-to-end Language generation》阅读笔记
相关概念:
1.What is natural language understanding (NLU)?
Natural language understanding (NLU) is a branch of artificial intelligence (AI) that uses computer software to understand input in the form of sentences using text or speech. NLU enables human-computer interaction by analyzing language versus just words.
NLU enables computers to understand the sentiments expressed in a natural language used by humans, such as English, French or Mandarin, without the formalized syntax of computer languages. NLU also enables computers to communicate back to humans in their own languages.
A basic form of NLU is called parsing, which takes written text and converts it into a structured format for computers to understand. Instead of relying on computer language syntax, NLU enables a computer to comprehend and respond to human-written text.
One of the main purposes of NLU is to create chat- and voice-enabled bots that can interact with people without supervision. Many startups, as well as major IT companies, such as Amazon, Apple, Google and Microsoft, either have or are working on NLU projects and language models.
2.What are BIO and BILOU?
BIO and BILOU encodings represent the most popular encoding schemas. The BIO encoding schema is presented in Fig., where B denotes the beginning of a segment, I represents the inside of a segment, including the ending word, and O stands for the word that does not belong to any segment.
(B - 'beginning';I - 'inside';L - 'last';O - 'outside';U - 'unit')

3.What is the exposure bias?
Exposure bias refers to the train-test discrep- ancy that seemingly arises when an autoregres- sive generative model uses only ground-truth contexts at training time but generated ones at test time.
4.What is the difference between Wikidata and DBpedia?
In more detail, DBpedia periodically retrieves information from the different chapters of Wikipedia by using statistic and data mining techniques, whereas Wikidata provides structured data to Wikipedia in real time (see Fig.)

5.BERT、GPT和BART的区别。
-
BERT模型是仅使用Transformer-Encoder结构的预训练语言模型(具备双向语言理解能力的却不具备做生成任务的能力)。
-
GPT模型是仅使用Transformer-Decoder结构的预训练语言模型(拥有自回归特性的却不能更好地从双向理解语言)。
-
BART模型是使用Transformer模型整体结构的预训练语言模型(在自然语言理解任务上表现没有下降,并且在自然语言生成任务上有明显的提高)。

6.什么叫做自回归?
自回归,全称自回归模型(Autoregressive model,简称AR模型),是统计上一种处理时间序列的方法, 是用同一变量之前各期的表现情况,来预测该变量自己本期的表现情况。 因为这不是用来预测其他变量,而是用来预测自己,所以叫做自回归。
摘要
关系抽取是信息抽取的一个重要任务,它可以从原始文本中抽取出实体之间的关系三元组,为知识库、事实检查和其他应用提供支持。然而,这通常需要一个多步骤的流程,可能会导致错误的累积或者只能处理少数几种关系类型。为了解决这些问题,本文提出了一个端到端的关系抽取模型REBEL,它是一个自回归的seq2seq模型。seq2seq模型已经在语言生成和NLU任务上表现出优异的性能,例如实体链接等。本文展示了如何通过将关系三元组转换为一个文本序列来简化关系抽取的问题,并且使用BART作为seq2seq模型的基础,使得REBEL能够抽取超过200种不同的关系类型。
1 Introduction
关系抽取:
-
从给定的文本中提取实体之间的语义关系,把非结构化原始文本转换为结构化数据,组成关系三元组(ei,rij,ej),这些数据可用于一系列下游任务和应用程序,例如知识库的构建等。
传统关系抽取被视为一个两步问题:
-
使用命名实体识别(NER)从文中抽取实体。
-
使用关系分类(RC)判断提取的实体之间是否存在关系。
传统关系抽取所面临的问题:
-
识别哪些实体真正共享一个关系可能会成为瓶颈,因为这需要额外的步骤,例如负抽样和注释等。
端到端方法是一个多任务的方法,可以同时处理上述两个任务,即让一个模型同时在两个目标上进行训练。
端到端方法所面临的问题:
-
通常比较复杂,有一些专注于任务的元素,需要根据关系或实体类型的数量进行适应。
-
不够灵活,无法处理不同性质的文本(句子级别与文档级别)或领域。
-
通常需要很长的训练时间,以便对新数据进行微调。
本文提出了一种将关系抽取视为seq2seq任务的自回归方法(REBEL, Relation Extraction By End-to-end Language generation),以及一个利用自然语言推理模型得到的大规模远程监督数据集(REBEL)。REBEL是一个简单而有效的端到端关系抽取模型,它将三元组作为文本序列来处理。它利用一个大的银色数据集对一个Transformer(BART)进行预训练,然后在几个周期内微调,在多个RE基准上取得最佳的性能。它的简单性也使得它能够灵活地适应不同的领域和更长的文本。由于在微调阶段仍然使用预训练的模型权重,因此不需要重新训练模型特定的组件,节省了训练时间。此外,REBEL不仅可以用于关系抽取,还可以用于关系分类,达到与其他方法相当的结果。本文提供了REBEL的模型代码和预训练权重,它可以抽取超过200种关系类型,也可以很容易地在新的RE和RC数据集上进行微调。
2 Related work
2.1 Relation Extraction
关系抽取与关系分类的定义:
-
RC(Relation Classification):从给定上下文中两个实体之间进行关系分类。
-
RE(Relation Extraction ):从原始文本中提取实体之间关系三元组,没有给定实体,也称为端到端关系提取。
关系抽取的方法:
-
流水线技术(pipeline):早期的工作利用CNN、LSTM挖掘语义关系,并对给定的实体进行关系分类。 目前已有工作开始使用transformer模型。
-
早期的端到端方法:对输入文本中所有单词对进行分类,使用表格表示或表格填充,将任务转化为填充一个表格(关系)的格子,其中行和列是输入中的单词。
-
利用联合训练的流水线技术:联合训练NER和RC,比如Eberts and Ulges (2021)使用了一个流水线方法(文档级RE),联合训练了一个多任务模型,利用共指消解在实体级别而不是提及级别进行操作。
关系抽取是一个重要的任务,但是由于缺乏统一的基准和任务定义,导致了不同的数据集和评估方法,使得模型之间的比较变得困难。Taillé等人(2020)分析了目前存在的不同问题,并且尝试建立一个RE的评估框架,以实现系统之间的公平对比。本文将遵循他们的指导,除非特别说明,否则使用严格的评估,即只有当头实体和尾实体以及关系和实体类型(如果数据集中有的话)均被正确抽取(即完全与注释重叠)时,才认为一个关系是正确的。
2.2 Seq2seq and Relation Extraction
流水线技术和表格填充方法面临的挑战:
-
它们通常假设每个实体对之间最多有一种关系类型,而且多分类方法不考虑其他的预测。例如,它们可能预测同一个头实体有两个“出生日期”,或者预测一些不兼容的关系。此外,它们需要推断所有可能的实体对,这可能会变得计算代价昂贵。
使用Seq2seq方法来进行RE(Zeng等人,2018, 2020; Nayak和Ng, 2020)可以有效地解决一些问题。这些方法可以利用解码机制来避免重复输出相同的实体,以及根据之前的预测来调整未来的解码,从而隐含地消除不一致的预测。
Seq2seq方法存在的问题:
-
Zhang等人(2020)指出,将三元组转换为文本序列需要一个线性化的过程,而这个过程可能是有些随意的,比如按照字母顺序。Zeng等人(2019)对这个问题进行了研究,他们使用了强化学习来确定三元组的抽取顺序。
-
由于在训练过程中,预测总是依赖于正确的输出,seq2seq方法会受到暴露偏差的影响。Zhang等人(2020)提出了一个树解码的方法,可以缓解这个问题,同时仍然保持了seq2seq方法的自回归性质。
seq2seq Transformer模型,例如BART(Lewis等人,2020)或T5(Raffel等人,2020),已经被应用于NLU任务,如实体链接(Cao等人,2021)、AMR解析(Bevilacqua等人,2021)、语义角色标注(Blloshmi等人,2021)或词义消歧(Bevilacqua等人,2020)等。通过将这些任务重新定义为seq2seq任务,这些模型不仅展现了优异的性能,还体现了seq2seq模型的灵活性,它们不需要依赖于预先定义的实体集合,而是利用解码机制,可以轻松地处理新的或未见过的实体。
本文提出了一个编码器-解码器的模型,它可以解决一些之前的seq2seq方法在RE上遇到的问题。它利用注意力机制来处理长距离的依赖和对之前解码的输出的关注(或忽略)。它还设计了一种新的三元组线性化方法,保证了三元组的顺序是一致的,使得模型能够更好地利用编码的输入和解码的输出。
3 REBEL
-
使用BART-large(Lewis et al., 2020)作为基础模型,将关系抽取和分类视为一个生成任务,输出输入文本中存在的每个三元组。
-
输入:编码器接收输入数据序列,即数据集中的文本。
-
输出:解码器产生输出数据序列,即线性化的三元组。
-
预训练模型:BART。
-
损失函数:Cross-Entropy。
在一个翻译任务中,teacher forcing利用两种语言的文本对,通过将解码的文本依赖于输入。在训练时,编码器接收一种语言的文本,解码器接收另一种语言的文本,在每个位置输出下一个token的预测。
在本文的方法中,将一个包含实体以及它们之间隐含的关系的原始输入句子,翻译为一组明确指代这些关系的三元组。因此,需要将三元组表达为一个token序列,由模型进行解码。本文设计了一种可逆的线性化方法,使用特殊的token,使得模型能够以三元组的形式输出文本中的关系,同时最小化需要解码的token的数量。
如果x是输入句子,y是根据第3.1节中解释的方法将x中的关系线性化的结果,那么REBEL的任务是给定x,自回归地生成y:

通过在这样一个任务上微调BART,使用与摘要或机器翻译中相同的交叉熵损失,最大化给定输入文本生成线性化三元组的对数似然。
3.1 Triplets linearization
-
<triplet>标记了一个新的三元组的开始,后面跟着一个新的头实体。
-
<subj>标记了头实体的结束和尾实体的开始。
-
<obj>标记了尾实体的结束和头实体与尾实体之间关系的开始。
本文采用了一种新的三元组线性化方法,它按照实体在输入文本中出现的顺序来排序和分组三元组。对于每个头实体,先输出它与文本中第一个出现的尾实体之间的关系,然后输出它与其他尾实体之间的关系。不需要每次都重复头实体的名字,这样可以缩短解码文本的长度。当一个头实体的所有关系都输出完毕后,开始输出文本中下一个头实体的关系,直到所有的三元组都被线性化。
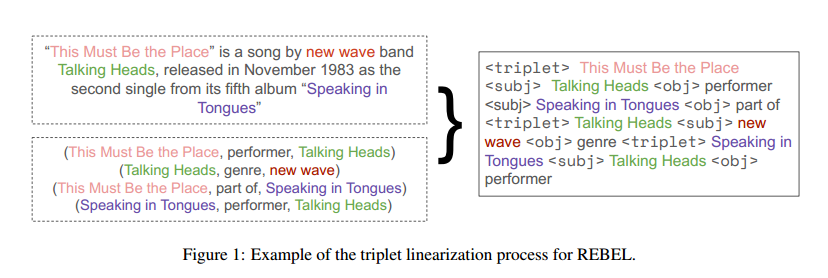

如上图所示,同一个头实体“This Must Be the Place”对应两个尾实体、两个关系。
依据本文的方法,可以通过特殊的token来恢复原始的三元组。在RE数据集中,三元组中不仅包含实体,还包含实体类型,需要模型一起预测。为了实现这一点,可以对算法1做一些修改,用不同的token来表示不同的实体类型,如<per>或<org>,分别代表人或组织,来替换<subj>和<obj>,并用它们来标记实体的类型。
3.2 REBEL dataset
自回归变换模型,如BART或T5,在不同的生成任务(如翻译或摘要),表现得很好,但一方面,它们需要大量的数据来训练;另一方面,端到端的关系抽取数据集是稀缺的,通常很小。
T-REx数据集(Elsahar 2018):为了解决大规模的RE数据集的缺乏,一种方法是从DBpedia摘要中抽取实体和关系,但是这种方法的注释质量有些问题。首先,由于使用了一个过时的实体链接工具(Daiber等人,2013),导致了实体消歧的错误。这样就会影响到基于这些实体的关系抽取,造成关系的缺失或错误。其次,这种方法大多数情况下是通过假设两个实体在文本中的共现就意味着它们之间存在关系,而这种假设并不一定成立。
REBEL数据集:本文通过扩展他们的流程来克服这些问题,创建了一个大的银色数据集,用于REBEL的预训练。首先,使用wikiextractor (Attardi, 2015)提取Wikipedia摘要,即每个Wikipedia页面目录前的部分。然后使用wikimapper,将文本中作为超链接的实体、日期和值,链接到Wikidata实体。接着,从Wikidata中抽取出这些实体之间存在的所有关系,作为三元组的标注。该流程可以使用任何语言的Wikipedia dump,支持多语言的关系抽取;使用多核处理和SQL来处理Wikidata dump,避免了内存问题,提高了抽取效率;使用了最新的实体链接工具,减少了实体消歧的错误,提高了关系抽取的质量。
从Wikidata中抽取关系的方法并不总是能够反映文本中的真实关系。Elsahar等人(2018)认为这种方法可以得到高质量的数据,但是实际上,对于一些常见的关系,如国家或配偶,这种方法会产生很多噪声。本文也发现了这种方法的一些注释问题。本文利用一个预训练的RoBERTa (Liu等人,2019)自然语言推理(NLI)模型来解决这个问题,并使用它来过滤那些不是由Wikipedia文本所蕴含的关系。对于每个三元组,输入包含两个实体的Wikipedia摘要中的文本以及三元组(主语+关系+宾语,用<sep>标记分隔)。
本文的数据抽取流程虽然不是完美的,可能会保留一些噪声的关系,或者遗漏一些文本中存在的关系,但是它可以自动地收集大量的实体和关系作为银色数据集,这对于训练本文的模型是足够的。本文的RE数据集创建工具被命名为cRocoDiLe。
4 Experimental Setup
数据集:4个RE数据集;1个RC数据集;预训练数据集。

评估指标:Recall、Precision、micro-F1。评估策略参考Taillé et al. (2020)。
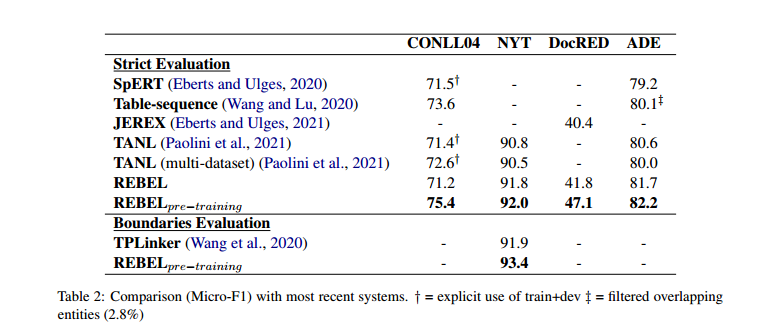
5 Results
使用有预训练的REBEL比没有使用预训练的REBEL效果好。
在句子级上进行预训练的REBEL在DocRED上的表现仍然具有竞争力。