《SagDRE: Sequence-Aware Graph-Based Document-Level Relation Extraction with Adaptive Margin Loss》论文阅读笔记
代码
原文地址
关键参考文献:
摘要
关系抽取(RE)是许多自然语言处理应用的重要任务,它的目标是从文档中抽取出实体之间的关系。文档级RE任务面临着许多挑战,因为它不仅需要跨句子进行推理,还要处理同一文档中存在的多种关系。为了更好地捕捉文档中的长距离相关性,现有的最先进的文档级RE模型都采用了图结构。本文提出了一种新的文档级RE模型,名为SagDRE,它能够有效地利用文本中的原始顺序信息。该模型通过学习句子级别的有向边来表示文档中的信息流,同时利用词级别的顺序信息来编码实体对之间的最短路径。此外,本文还设计了一种自适应边距损失函数,来解决文档级RE任务中的长尾多标签问题,即一个实体对可能在一个文档中涉及到多种关系,而且有些关系比较常见。该损失函数能够有效地增加正负类之间的间隔。本文在多个领域的数据集上进行了实验,结果表明本文的方法具有很好的效果。
1 INTRODUCTION
关系抽取(RE):从文本中识别并提取实体之间的语义关系。
句子级RE:只关注单个句子内的实体关系。
文档级RE(DocRE):需要从多个句子中抽取实体关系。
DocRE面临的挑战1:
-
在一个文档中,同一个实体可能有多次提及,但并非所有的提及都与目标关系有关,这就要求RE模型能够筛选出文档中最相关的信息。
-
文档中的实体提及可能分布在不同的句子中,这就要求RE模型能够有效地捕捉长距离的语义信息。
目前应对挑战1的方法:
-
采用基于图的模型来表示文档,这些方法使用了双向边的规则图结构来传递特征,而忽视了原始文本中的序列特征。由于图结构的置换不变性,这些方法无法编码序列信息,这可能限制了文档级RE任务的性能。
DocRE面临的挑战2:
-
同一实体对在文档中可能涉及多个不同的关系,导致多标签的问题。
目前应对挑战2的方法:
-
将多标签问题拆分为多个二分类问题,根据预测概率是否超过一个全局阈值来确定是否赋予相应的标签。但是,这个全局阈值往往是基于经验或在验证集上调节的,可能并不适用于所有的情况。另外,多标签问题还存在一个常见的现象,就是标签的长尾分布。有些关系的训练样本很少,而有些关系的训练样本很多。基于常规概率分布的损失函数容易使模型对热门的关系过拟合,而对冷门的关系欠拟合。
本文提出了一种序列感知图文档级关系抽取模型(SagDRE),它能够利用原始文本的序列信息来进行文档级关系抽取。对于一个给定的文档,首先构建了一个带有有向边的序列感知图,用于表示文档中句子之间的序列关系。本文在图中添加了从前向后的有向边,连接每一句的根节点,并用注意力机制来学习边的权重。基于这样的图结构,本文使用图卷积神经网络和多头自注意力来编码文档的局部和全局特征。为了利用词级的序列信息,SagDRE在图上寻找从头实体到尾实体的条最短路径,并用原始的词序和一些辅助词来重建路径。然后,用LSTM来对路径进行编码,并用多头注意力层来对路径进行加权,从而突出重要的路径。最后,将路径编码和其他特征拼接起来,作为预测的输入。为了解决文档级关系抽取中的长尾多标签问题,本文提出了一种基于Hinge Loss的自适应边界损失函数。它的思想是为每一对实体之间的正类和负类学习一个分隔类。当一个样本被错误地分类或者分类在分隔类的边界附近时,就会触发自适应边界损失函数。通过这个损失函数的优化,可以通过分隔类来增加正类和负类之间的间隔。
在实验部分,本文在三个来自不同领域的文档级关系抽取数据集上对SagDRE进行了评估。实验结果表明,SagDRE模型在所有数据集上都显著优于现有的最先进的模型。通过消融实验,发现自适应边界损失函数和序列组件是提高模型性能的关键因素。
2 RELATED WORK
基于BERT的方法:
-
Tang等人构建了一个分层推理网络,利用BERT的输出来从实体、句子和文档三个层面进行推理。
-
Ye等人在BERT的基础上引入了共指信息,以提升其共指推理的能力。
-
Zhou等人设计了一种自适应阈值损失函数,它能够动态地调整正负样本的划分阈值。
基于图的方法:
-
Sahu等人首次在文档级关系抽取任务中引入了图结构,它通过语言工具构建了包括共指边在内的各种边,从而捕获句间和句内的依赖关系,并使用图卷积神经网络进行特征学习。
-
Guo等人利用注意力机制来自动构建图中的边,并关注图中与关系推理相关的子结构。
-
Zeng等人提出了一种双图模型,分别构建提及级和实体级的图,来预测文档中的关系,而不是简单地使用词级的图。
-
Christopoulou等人构建了一个包含不同类型节点和边的图,并采用了一种面向边的图神经网络来进行文档级关系抽取。
-
Nan等人则应用了一种迭代细化策略来聚合多跳信息进行推理。
-
Zhou等人提出了一种全局上下文增强的图卷积网络,能够考虑全局上下文信息进行关系推理。
3 PRELIMINARY
3.1 Graph Convolutional Networks
给定一个图
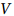


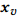



其中
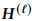


3.2 Relation Extraction Task Formulation
文档级关系抽取的任务是这样定义的:给定一个包含








4 SAGDRE
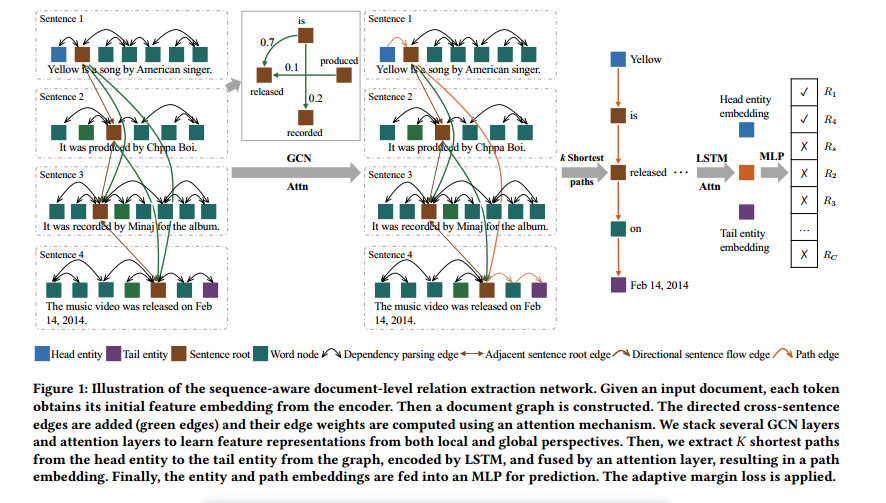
4.1 Sequence-Aware Graph Construction
为了更好地捕捉DocRE任务中的长距离信息,现有的DocRE方法通常采用基于依赖解析器[4, 31]构建的无向图结构来表示文档图,从而增加了头尾实体对之间的连通性。然而,这种构建图的方式无法显式地反映语言序列信息,而且双向图的排列不变性特性使得捕捉文本中表达的序列信息更具挑战性。
将文本中的原始序列信息进行编码是至关重要的,因为改变词的顺序或句子的顺序可能会导致一对实体之间的关系语义发生变化。如果忽略了文本中的序列信息,可能会对基于图的关系抽取模型的性能产生负面影响。
为了保持头尾实体对之间的高连通性,并有效地编码原始序列信息,本文提出了一种能够捕捉句子级序列信息的序列感知文档图。具体来说,给定一个文档,首先用一个编码器对文档中的每个词进行上下文特征编码:

其中


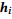
接下来,构建一个文档图,它由两类节点组成:词节点和实体节点。文档中的每个词都对应一个词节点,它的编码特征作为节点特征。文档中的每个实体都对应一个实体节点,它的节点特征由它的提及中的词的特征的平均值得到。
图中有两类边:双向边和有向边。双向边来自三个来源:依赖句法树、相邻句子的根节点和实体-词关系。把文档中的每个句子输入到一个依赖解析器中,得到一个依赖句法树。在句法树中,每对相连的词之间都有一条双向边。然后,在相邻句子的依赖句法树的根节点之间也加上双向边,因为相邻句子之间有紧密的上下文关系。最后,在每个实体和它的提及中的词之间也加上双向边。在这个图中,双向边的权重都是1,表示节点之间有强连接。
有向边用来捕获文档中的句子级序列信息。具体来说,在前面的句子根节点和后面的句子根节点之间加上前向边,因为文档中的信息通常是从前面的句子向后面的句子传播的。但是,并不是所有的句子都和前面的句子密切相关,所以使用一个注意力机制来自动学习给定任务下每对句子之间的紧密程度,并把得到的相似度分数作为这些有向边的权重。
具体地,对于两个句子根节点 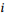



其中 
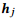
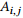

4.2 Local and Global Feature Encoding
本文根据特征矩阵


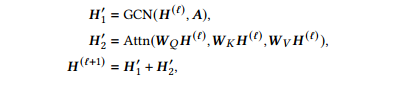
其中 





4.3 Sequence-Aware Path Encoding
为了解决文档图中实体之间距离过长和信息不相关的问题,本文提出了一种基于顺序感知路径的编码方法,能够有效地捕捉实体关系的推理信息。给定一个图和一对实体




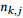

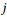



其中,


由于并非所有路径都包含用于关系推理的相关信息,因此本文在𝐾最短路径编码上使用多头注意层来识别最相关的路径。将这一过程表述为:
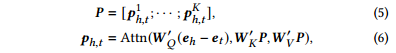
其中


该注意力层以从头实体到尾实体的实体编码向量作为查询,并将其加权聚合为最终的实体关系表示。
4.4 Relation Prediction Head
本文使用一个关系预测头来预测一对实体之间的关系。预测基于两个实体的特征表示和它们的聚合路径编码。沿用之前的方法[43],本文将两个实体的编码




本文计算所有关系类别的预测值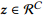

其中



其中





4.5 Adaptive Margin Loss

大多数现有的关系抽取模型都是基于概率的,它们输出

为了克服多类学习任务中的长尾问题,已经有许多 Hinge 损失的变体被提出,并应用于各个领域。Hinge 损失不是对概率分布进行建模,而是构造一个最大间隔分类器。然而,这些 Hinge 损失的变体不能直接应用于多标签学习问题,其中一个实例可能同时属于多个类别。
本文提出了一种多标签学习任务的适应性边缘损失函数,它能够增加正类和负类之间的间隔。对于任意一对实体 




对于一对实体

其中
当预测正确(即



5 EXPERIMENTS
5.1 Experiments on the General Domain Dataset

Datasets:
-
DocRED。
Evaluation Metrics:
-
Ign F1和 F1 scores,两个指标都是值越高越好。
Baseline Models:
-
基于序列的模型: CNN-GloVe、BiLSTM-GloVe、BERT、ATLOP-BERT、CorefBERT和HIN-BERT。
-
基于图的模型: AGGCN-GloVe、EoGGloVe、LSR-GloVe/BERT和GAIN-GloVe/-BERT。
SagDRE Setups:
-
使用 Huggingface 的 Transformers来实现 BERT 模型,并在最后的预测层加入了保留率为 0.6 的 dropout。采用 AdamW 优化器对 SagDRE 模型进行优化,学习率设置为 1e-3。在使用 BERT 编码器的训练过程中,对前 6% 的步骤采用线性预热,然后逐渐降低学习率至 0。在使用 Glove 嵌入的情况下,根据验证集上的 F1 值是否提升来调整学习率。所有的超参数都是在验证集上调节得到的。使用一块 Tesla V100 GPU 来训练所有的 RE 模型。
Main Results:

本文在表 2 中总结了各个模型的比较结果。结果表明,SagDRE在所有方面都超过了之前的最先进模型。与没有使用预训练 BERT 模型的方法相比,GAIN-GloVe 是基准方法中性能最好的一个。SagDRE-GloVe 在验证集上分别提高了 0.64% 和 1.4%,在测试集上分别提高了 1.19% 和 1.11%,相比 GAIN-GloVe,这里的评价指标分别是 Ign F1 和 F1。所有的方法在使用预训练 BERT 模型后都有了显著的提升。与基准模型相比,SagDRE-BERTBASE 在验证集和测试集上也取得了更好的性能。特别地,与 ATLOP-BERTBASE 相比,本文的模型在验证集上分别提高了 1.1% 和 1.12%,在测试集上分别提高了 0.8% 和 1.02%,这里的评价指标也是 Ign F1 和 F1。两组比较结果都表明,本文提出的方法无论是使用 GloVe 嵌入还是预训练的Transformer模型,都能带来一致的性能提升。值得注意的是,当K = 1时,SagDRE 的结果与K = 3时相近。这是因为最短路径已经包含了推理所需的大部分信息,而且在使用预训练的 Bert 模型时,还能获得丰富的上下文信息。
5.2 Experiments on Biomedical Datasets
Datasets:
-
CDR和CHR。
Evaluation Metrics:
-
F1 scores。
Baseline Models:
-
CNN-BioGloVe、BiLSTM-BioGloVe、EoGBioGloVe、GAIN-GloVe、ATLOP-SciBERT和SciBERT。
SagDRE Setups:
-
实验设置基本沿用了第 5.1 节的方法,但也有一些不同之处。这里编码器采用了 SciBERT,它是在大量科学领域的标注语料上预训练得到的语言模型。用 AdamW 算法优化了 SagDRE 模型,初始学习率设置为 1e-3。在训练过程中,先对前 6% 的步骤进行线性预热,然后再将学习率逐渐降为 0。为了节省计算资源,在评估 SagDRE 模型时只使用了 K = 1 的设置。
Main Results:
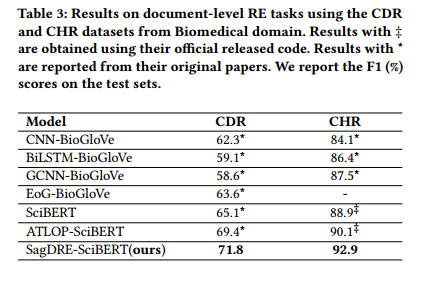
结果总结在表3中。SagDRE在这两个生物医学RE数据集上的表现始终优于以前最先进的模型。与之前的最佳模型ATLOP-SciBERT相比,提出的SagDRE在CDR和CHR上分别高出2.4%和2.8%。这证明了本文提出的方法在生物医学数据集上的有效性。
5.3 Ablation Study of SagDRE

为了研究每个组件对整体模型性能的影响,本文基于 SagDRE 模型进行了消融实验。分别移除了 GNN 编码器、有向边、路径 LSTM、路径增强和自适应边距损失这五个组件,并使用 DocRED 的验证集评估了不同的模型配置。还测试了一个不包含任何序列组件(即有向边和路径 LSTM)的 SagDRE 模型,以检验序列信息的重要性。本文在 SagDRE-GloVe 和 SagDRE-BERTBASE 两种模型上都进行了消融实验,结果如表 4 所示。
从表 4 中可以看出,本文提出的每个组件都对模型性能有正向的贡献。其中,最重要的两个组件是自适应边距损失和序列组件。如果用最佳阈值的交叉熵损失或者中的自适应阈值损失来替换自适应边距损失,F1 分数会分别下降 2.43% 和 4.31%。如果移除序列组件,性能也会下降 2.39%,这说明文本中的序列信息对于文档级关系抽取任务是非常关键的。具体来说,句级和词级的序列信息都能提升 SagDRE 模型的性能,这从移除有向边和路径 LSTM 时的性能降低可以看出。
5.4 Parameter Study in Adaptive Margin Loss

本文提出了一种自适应边距损失,其中有一个超参数
5.5 Error Analysis
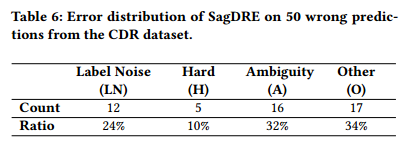

为了更好地理解 SagDRE 的瓶颈并为未来的工作提供启示,本文对 SagDRE 产生的错误进行了一个案例研究。这里选择了 CDR 数据集,因为它是由领域专家标注的,所以标签噪声可能最少。本文随机挑选了 SagDRE 的 50 个错误预测,并分析了造成错误的原因。把它们归为三个主要原因和一个其他原因:1) 标签噪声 (LN),这类错误是由于实体对被领域专家标注错误导致的,2) 困难 (H),这类错误是由于推断实体对之间的关系需要额外的知识或高级推理导致的,3) 模糊 (A),这类错误是由于文档对关系的表达不清晰导致的,4) 其他 (O),这类错误包括了所有其他原因导致的错误。表 6 显示了这些错误的分布情况。表 7 给出了每类错误的一些例子。从本文的分析中,可以发现大部分错误没有明显的原因。但是,注意到,模型对含有某些关键词的实体对更容易出错。例如,文档 #24897009 中说:“伊索尼酰胺已知会导致...很少...多神经病变”。否定词“很少”可能使模型误判实体对之间没有关系。本文还发现其他一些影响模型判断的关键词,如否定词“没有”和表示不确定性的词“可能”。
文档的模糊性是导致错误的另一个主要原因。这类错误主要出现在药物副作用事件的报告中。比如,文档 #3297909 记载了一名男子在接触噻苯达唑后患上了黄疸,文档 #24729111 记载了一名男子在用胺碘酮治疗后发生了呼吸衰竭。这两个案例中,症状是否由药物引发并不清楚,而且专家对这两个案例的标注也不一样。训练数据中可能还存在更多这样的案例,导致模型无法做出一致的预测。
另外,一些领域专家提供的标签可能也有错误。例如,文档 #24618873 明确地说明了疾病和药物之间有因果关系。但是,这对实体的标签却是“无关的”。
还有一些难以处理的案例,可能需要借助外部知识。例如,文档 #24659727 表示,在接受给定治疗的 57 只狗中,只有 1 只出现了症状,所以这种关系在统计上是不显著的。要正确地标注这对症状-药物实体,模型需要理解“3%”的概率太低,不能证明这种关系。常识抽取和数字抽取的研究或许可以帮助解决这种情况。
6 CONCLUSION
本文提出了一种基于顺序信息的文档级关系抽取模型,命名为 SagDRE。SagDRE 同时考虑了文档中句子和词的顺序信息。为了利用句子的顺序信息,本文在文档图中引入了有向边,并用注意力机制学习它们的权重。这些有向边能够反映文档中句子的逻辑流程。为了利用词的顺序信息,SagDRE 从头实体到尾实体抽取并重构了增强的最短路径,并用 LSTM 编码它。为了克服常规损失函数在优化关系抽取模型时的不足,本文设计了自适应边际损失。这个损失函数引入了一个阈值类,并放大了正类和负类之间的边际。在两个来自通用和生物医学领域的文档级关系抽取数据集上,本文的方法都取得了有效的结果。SagDRE 的消融实验表明,本文提出的每个组件都有助于提高模型性能。其中,自适应边际损失和顺序信息的利用是最重要的贡献。